Daten auf fremden Webseiten, die in Tabellenform daherkommen,
extrahiert das Modul HTML::TableExtract ohne große Klimmzüge.
Der CGI-Helfer CGI zeigt sie anschließend umgewandelt wieder
im Browser an.
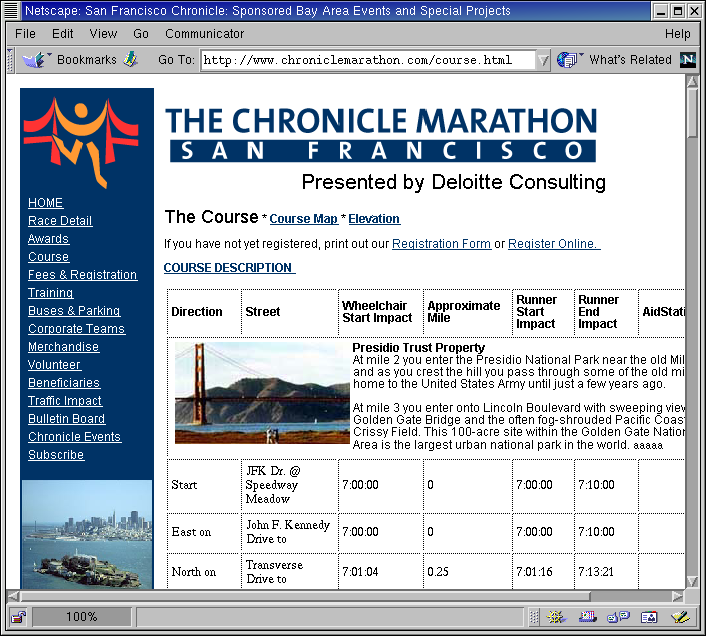
Am Tag vor dem Marathon in San Francisco wollte ich herausfinden, wann ungefähr ich während des Laufs an der Straßenkreuzung vorbeikäme, an der Angelika auf mich warten würde, um mir beim Leiden zuzusehen. Nun gab es vom Veranstalter einen Streckenplan auf [2] (Abbildung 1), der genau jede Wendung der Strecke mit einer Meilenangabe auflistete.
| |
| Abbildung 1: Die Originalseite des Marathonveranstalters |
In einer riesigen Tabelle stand da nun allerlei Unrat, aber ich wollte nur die Namen der Straßenkreuzungen und die entsprechenden Meilenangaben extrahieren und daraus eine neue Tabelle erstellen, die für eine Reihe von geschätzten Laufgeschwindigkeiten Ankunftszeiten über alle Straßenkreuzungen anzeigte.
Statt wild mit regulären Ausdrücken herumzufuchteln, erinnerte ich mich
an [3] und [4], in denen vor einiger Zeit das Modul HTML::TableExtract von
Matthew Sisk vorgestellt wurde, das elegant Daten aus Tabellen völlig
fremder Webseiten extrahiert. Statt tiefer in den HTML-Code
vorzudringen, sagt man einfach: ``Ich hätte gerne die Spalten
Direction, Street und Mile aus der ersten Tabelle auf dieser
Seite, die diese Spalten enthält.'' -- Fertig! HTML::TableExtract wird
dann den HTML-Code parsen, die Tabelle ausfindig machen und die
gefundenen Spalten mit den dazugehörigen Daten extrahieren. Dabei bietet
es reinsten Bedienungsluxus, denn die Spaltenüberschriften können selbst
in falscher Reihenfolge dastehen oder statt mit <TH> mit
<TD>
ausgezeichnet sein -- HTML::TableExtract findet sie auch dann,
wenn sie sich
noch so gut verstecken.
Listing mara zeigt ein CGI-Skript, das die Seite des
Marathon-Veranstalters vom Netz holt, die gewünschten Daten extrahiert,
für einige vorgeschlagene Laufgeschwindigkeiten die Ankunftszeiten
an allen Straßenkreuzungen
vorhersagt und alles schließlich als HTML-Tabelle ausgibt, die man sich
im Browser ansehen kann.
Da mein Web-Provider mir nicht erlaubt, Perl-Module im Root-Verzeichnis
zu installieren, habe ich mir einfach /home/mike/perl eingerichtet,
um Zusatzmodule zu installieren, die die Perl-Installation des
Providers nicht führt. Statt mittels
perl -MCPAN -eshell
installiere ich neue Module mit
perl -e'use lib "/home/mike/perl"; \
use CPAN; shell'
unterhalb des lokalen Verzeichnisses. Später lasse ich meine Skripts einfach
use lib '/home/mike/perl';
aufrufen, bevor sie lokal installierte Zusatzmodule nutzen. Das heutige
Skript verwendet LWP::Simple zum Einholen von Webseiten,
HTML::TableExtract zur Datenextraktion und Date::Calc zur
Berechnung von Zeitangaben, die die CPAN-Shell alle flugs installiert:
cpan> install LWP::Simple
cpan> install Date::Calc
cpan> install HTML::TableExtract
Die Zeilen 9 bis 13 im Skript mara
ziehen die notwendigen Zusatzmodule herein.
Zeile 10 weist LWP::Simple mit () an, keine Funktionen in den
Namensraum des Skripts zu abzulassen -- andernfalls ergäbe sich
ein Konflikt mit der Funktion head(), die sowohl LWP::Simple
als auch das nachher hereingezogene Modul CGI exportieren. Letzteres
weisen wir mit qw(:all *table *TR) an, reihenweise Funktionen
zu exportieren, um später bei der HTML-Ausgabe
Tipparbeit zu sparen.
mara nutzt ausserdem CGI::Carp in Zeile 13 mit dem Tag
fatalsToBrowser und weist so das
CGI-Skript an, bei auftretenden Fehlern eine detaillierte
Fehlerbeschreibung über den Browser auszugeben -- eine nützliche
Sache während der Skriptentwicklung, die aber später aus Sicherheitsgründen
aus der Produktionsumgebung verschwinden sollte.
Die Zeilen 15 bis 18 legen Konstanten fest: $URL bestimmt
den URL zur Webseite des Marathonveranstalters, @START_TIME
legt mit 7 Stunden, 0 Minuten und 0 Sekunden fest, dass der Marathon
punkt 7 Uhr morgens losgeht und @SPEEDS enthält sechs
verschiedene Laufgeschwindigkeiten,
von recht flotten 7.5 Meilen pro Stunde (etwa 12 km/h) bis runter
zum relaxten Dauerlauf von 5.0 Meilen pro Stunde (etwa 8 km/h).
Zeile 20 holt mittels des voll qualifizierten Aufrufs von
LWP:Simple::get() die HTML-Seite mit der
Streckentabelle vom Web und legt deren Inhalt
in $data ab. Falls etwas schief geht, bricht die() das Programm
ab. Nicht gerade freundlich für ein CGI-Programm, aber CGI::Carp
wird's schon richten.
Zeile 23 erzeugt ein neues Objekt vom Typ HTML::TableExtract und
legt fest, dass dieses später nach einer Tabelle suchen soll, die
die Spalten Direction, Street und Mile
(nicht unbedingt in dieser Reihenfolge) enthalten soll.
Zeile 25 wirft den Parser auf
die vom Netz geholten HTML-Daten an.
Zeile 27 nutzt exportierte Funktionen aus dem Modul CGI, um den CGI-Header
zu schreiben und die einleitetenden HTML-Tags herauszupusten.
start_table() in Zeile 28 schreibt nur <TABLE> mit
dem Attribut BORDER=1, das die Tabellenlinien sichtbar zeichnet.
Normalerweise schreibt die vom Modul CGI mit dem Tag
:all (Zeile 12) exportierte Funktion table() gleich
<TABLE>...</TABLE> und dazwischen die table()
als Parameter übergebenen Daten. In Zeile 28 liegen diese Daten
aber nicht vor und deswegen nutzen wir start_table, das das CGI-Modul
allerdings nur deswegen exportiert, weil wir in Zeile 12 das Tag
*table in der Exportliste angegeben haben. end_table()
haut auf denselben Sack und schreibt später nur </TABLE>.
Warum dann nicht gleich print "<TABLE>"
und print "</TABLE>"? Perl ist ein
Kunstwerk und HTML eine Bausünde -- beides vermixe ich nicht gerne.
Die in Zeile 32 aufgerufene
rows()-Methode des HTML::TableExtract-Objekts gibt alle
Zeilen der ersten im HTML-Dokument gefundenen Tabelle zurück, die die
vorher in Zeile 24 festgelegten Spaltenüberschriften führt.
Die foreach-Schleife
neben dem Label ROW iteriert über alle Tabellenzeilen
und legt für jede Zeile in $row eine Referenz auf ein Array ab,
der als Elemente Werte für die gesuchten Spalten enthält.
$row->[0] ist der Inhalt der ersten Spalte (Himmelsrichtung),
$row->[1] der Inhalt der zweiten (Straße/Kreuzung) und
$row->[2] die Meilenangabe.
Die nicht angeforderten Spalten der Tabelle eliminiert HTML::TableExtract
praktischerweise schon vorher.
start_TR() in Zeile 34 leitet mit <TR> eine neue
Tabellenzeile in der HTML-Ausgabe des Skripts ein und ist ebenfalls
nur wegen der Tag-Angabe *TR in Zeile 12 verfügbar, da das Tag :all
sie nicht automatisch aus CGI exportiert.
Manche Tabellenzeilen des Marathonveranstalters enthalten leere
Spalten, diese spürt Zeile 37 auf und springt mit next ROW
gleich in den nächsten Durchgang der äußeren foreach-Schleife,
die die Zeilen der Eingangstabelle kontrolliert. Wegen des Modifizierers
/s findet /\s*/
auch ``leere'' Spalten, die Newline-Zeichen enthalten.
Zeile 40 schließlich gibt die Spalten eins und zwei der Originaltabelle zusammengefasst in Spalte eins der Ausgabetabelle aus. Außerdem schreibt sie die Meilenspalte der Originaltabelle als Spalte zwei der Ausgabetabelle.
Die Spalten drei bis acht der Ausgabetabelle
müssen wir erst berechnen: Hierfür iteriert Zeile 43 über alle
vorgegebenen Geschwindigkeiten in @SPEEDS und rechnet mittels der allen
wahren Ingenieuren bekannten Formel t = s/v die Anzahl der Sekunden
aus, die der Läufer bei der Geschwindigkeit v braucht, um
die in $row->[2] liegende Meilenzahl s abzuspulen. Multiplikation
mit 3600 macht aus den herauskommenden Stunden schnell Sekunden.
Um die aktuelle Uhrzeit zu berechnen, die sich ergibt,
indem man t Sekunden zur Startzeit 7:00 addiert, braucht man
zwar keinen Doktorhut in Mathematik, aber aus Faulheit nutzt mara die
Funktion Add_Delta_DHMS() aus dem Modul Date::Calc, die zu einem
vorgegebenen Datum mit Uhrzeit die angegebene Anzahl von Tagen, Stunden,
Minuten und Sekunden addiert und das Ergebnis im Format
Jahr, Monat, Tag, Stunde, Minuten, Sekunden als Liste zurückgibt.
Today() füllt mit dem heutigen Kalendertag eine sinnvolle Datumsangabe ein.
Die sprintf-Funktion macht daraus eine schöne als HH::MM
formatierte Uhrzeit und Zeile 48 gibt sie als nächste Tabellenspalte
aus. Dies wiederholt sich für die restlichen Geschwindigkeitselemente
in @SPEEDS und endlich schließt end_TR die aktuelle
Ausgabetabellenzeile mit </TR> ab.
Zeile 53 beendet schließlich mit end_table() die Ausgabetabelle
und mit end_html die HTML-Ausgabe des CGI-Skripts. Das Ergebnis
des im cgi-bin-Verzeichnis des Webservers installierten Skripts,
das der Browser über den URL http://localhost/cgi-bin/mara aufruft,
zeigt Abbildung 2.
Meine eigene Geschwindigkeit lag dann doch eher bei knapp 6 Meilen pro Stunde (9.5 km/h). Das Ergebnis findet ihr unter [2]. Rennt fleißig Marathons, seid keine Weicheier!
01 #!/usr/bin/perl
02 ##################################################
03 # mara -- Mike Schilli, 2001 (m@perlmeister.com)
04 ##################################################
05 use warnings;
06 use strict;
07
08 use lib '/home/mike/perl';
09 use HTML::TableExtract;
10 use LWP::Simple ();
11 use Date::Calc qw(Today Add_Delta_DHMS);
12 use CGI qw(:all *table *TR);
13 use CGI::Carp qw(fatalsToBrowser);
14
15 my $URL =
16 "http://www.chroniclemarathon.com/course.html";
17 my @START_TIME = (7,0,0); # 7:00 geht's los
18 my @SPEEDS = (7.5, 7.0, 6.5, 6.0, 5.5, 5);
19
20 my $data = LWP::Simple::get($URL) or
21 die "Fetching $URL failed";
22
23 my $te = new HTML::TableExtract(
24 headers => [qw(Direction Street Mile)]);
25 $te->parse($data);
26
27 print header(), start_html();
28 print start_table({border => 1});
29 print th(["Where", "Mile", @SPEEDS]);
30
31 # Reihen der ersten passenden Tabelle
32 ROW: foreach my $row ($te->rows) {
33
34 print start_TR();
35
36 foreach my $col (@$row) {
37 next ROW if $col =~ /^\s*$/s;
38 }
39
40 print td("$row->[0] $row->[1]"),
41 td($row->[2]);
42
43 foreach my $speed (@SPEEDS) {
44 my $secs = $row->[2] / $speed * 3600;
45 my $time = sprintf "%02d:%02d",
46 (Add_Delta_DHMS(Today(),@START_TIME,
47 0,0,0,$secs))[3,4];
48 print td($time);
49 }
50 print end_TR();
51 }
52
53 print end_table(), end_html();
 |
| Abbildung 2: Die ermittelten Streckendaten |
 |
Michael Schilliarbeitet als Software-Engineer bei Yahoo! in Sunnyvale, Kalifornien. Er hat "Goto Perl 5" (deutsch) und "Perl Power" (englisch) für Addison-Wesley geschrieben und ist unter mschilli@perlmeister.com zu erreichen. Seine Homepage: http://perlmeister.com. |