Statt in regelmäßigen Abständen mehrere Nachrichtenseiten nach Neumeldungen abzuklappern, überlässt man dies lieber einem News- Aggregator. Dieser bleibt mit RSS-Feeds verschiedener Webseiten auf dem Laufenden, macht seinen Herrn automatisch auf Neuigkeiten aufmerksam und blendet schon Gelesenes aus. Falls eine Website noch kein RSS-Feed hat, lässt sich mit einem neuen Perl-Modul einfach eines für private Zwecke basteln.
Die Informationsflut im Internet hat dazu geführt, dass kein Mensch mehr alles Angebotene lesen kann. Wer täglich zwei dutzend Websites auf neue Nachrichten abklappert, kann gleich seinen Job aufgeben.
Seit einiger Zeit hat es sich deshalb eingebürgert, dass Nachrichten-Sites ihre Schlagzeilen mit Links zu den eigentlichen Artikeln in sogenannten RSS-Feeds zusammenfassen und in maschinenlesbarem Format zur Verfügung stellen. RSS steht für RDF Site Summary, wobei RDF seinerseits für Resource Description Framework steht. RSS-Dateien enthalten XML, das sogenannte New-Aggregatoren maschinell einlesen und dem Benutzer als Zusammenfassung klickbare Schlagzeilen von Meldungen präsentieren, die dieser noch nicht gelesen hat.
Diese sogenannte Syndication, das Zusammenstellen und Bereitstellen von Nachrichten, die bereits woanders verfügbar sind, hilft, der Informationsflut Herr zu werden und enorm Zeit zu sparen.
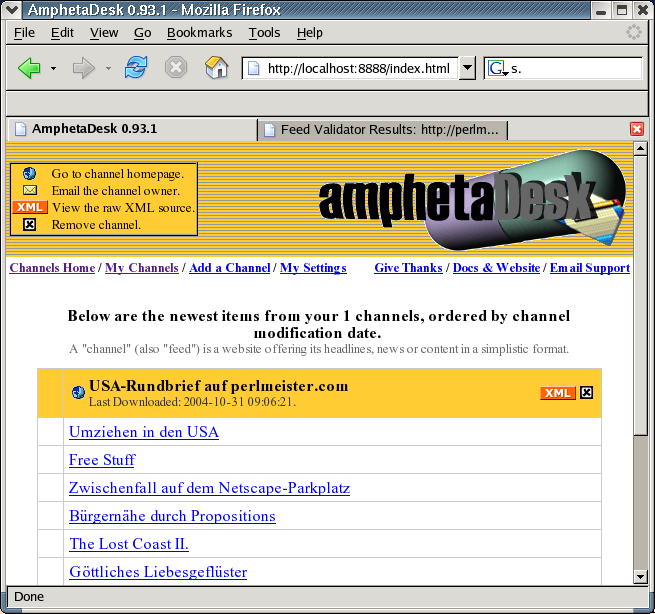
Bekannte Sites wie Slashdot und neuerdings sogar die Bildzeitung ([2]) bieten ihrerseits bereits RSS-Feeds an, die Aggregatoren wie Amphetadesk ([3] und Abbildung 1) in regelmäßigen Zeitabständen einsaugen, falls der Benutzer den Service 'abonniert', also den 'subscribe'-Knopf drückt.
| |
| Abbildung 1: Das Perlmeister-Newsfeed in Amphetadesk |
Doch nicht jede News-Seite hat ein RSS-Feed. Erwarten diese
Anbieter wirklich, dass Nutzer täglich vorbeischneien, um sich durch
die angebotenen Informationen zu wühlen? Das heute vorgestellte Modul
RssMaker stellt eine Funktion bereit, mit der man mit typischerweise
10 Zeilen Perl-Code aus einer Titelseite mit Schlagzeilen und URLs eine
RSS-Datei generieren kann. Per cronjob einmal am
Tag neu erzeugt, bietet es die Möglichkeit, die Website einem
News-Aggregator einzuverleiben, der dann, wie im 21. Jahrhundert üblich,
dem Leser eine Zusammenfassung bietet.
Die make-Funktion aus Listing
RssMaker.pm nimmt einen URL entgegen, unter
der die News-Site verfügbar ist, holt sie vom Web und wühlt sich
durch die darin enthaltenen HTML-Links. Jeden gefundenen bietet sie
mitsamt dem dargestellten Text einem vom Nutzer definierten Filter an, der
entscheidet, ob die Schlagzeile mit dem Link in die RSS-Beschreibung
aufgenommen wird oder nicht.
Falls ja, fügt das Skript neben der Schlagzeile und dem Link auch noch das letzte Modifikationsdatum der eingeholten Webseite in das Newsfeed ein, ein kleiner Trick, um Nachrichten mit einem Datum zu versehen, auch wenn diese selbst kein Datum führen.
Am Ende schreibt make die XML-Ausgabe in eine mit dem Parameter
output spezifizierte Datei, die später ein News-Aggregator aufgreifen
kann.
Um den HTTP-Zeitstempel des eingeholten Webdokuments in das vom RSS-
Format geforderte ISO-8601-Format umzuwandeln, scannt die Funktion
str2time aus dem Modul HTTP::Date zunächst das Stringformat (zum
Beispiel ``Tue, 26 Oct 2004 05:10:08 GMT'') ein und gibt die Unix-Zeit
in Sekunden zurück. Diesen Wert schnappt sich anschließend die
Funktion from_epoch() aus dem DateTime-Modul und erzeugt ein
neues DateTime-Objekt, das sich im Stringkontext magisch ins ISO-8601-
Format (``2004-10-26T05:10:08Z'') verwandelt.
Text in XML wird UTF-8-kodiert erwartet. UTF-8 ist kompatibel mit regulärem ASCII, solange keine Zeichen aus der zweiten Hälfte der 256-Zeichen-Tabelle enthalten sind. Die deutschen Umlaute stellen somit ein Problem dar: Werden nach ISO-8859-1 alle 256 Zeichen der ASCII-Tabelle mitsamt den Umlauten genutzt, ist die zweite Hälfte (129-256) nicht UTF-8-kompatibel.
RssMaker geht diesem Problem aus dem Weg, indem es dem
Programmierer erlaubt, die Kodierung im später erzeugten RSS-Dokument
festzulegen. Weist die analysierte Webseite HTML-Kodierungen wie
ü für ``ü'' auf, macht der HTML::TreeBuilder aus den
extrahierten Link-Texten ISO-8859-1. Das ``ü'' im Linktext
"Bohlen rügt Teppichluder" wird mit 252 kodiert.
Stünde in der später erzeugten RSS-Datei aber
<?xml version="1.0" encoding="utf-8"?>
und die ``ü''s wären mit ASCII 252 kodiert, gäbe das ein Problem.
Gibt der Programmierer der make-Funktion allerdings
encoding => "iso-8859-1" mit, steht später im XML-Dokument
<?xml version="1.0" encoding="iso-8859-1"?>
und als 252 kodierte ``ü''s werden vom News-Aggregator korrekt interpretiert.
Wie erzeugt man nun aus einer Nachrichtenseite mittels RssMaker.pm
ein RSS-Feed derselben? Listing rb2rss zeigt am Beispiel des
auf perlmeister.com publizierten Amerika-Rundbriefs, dass hierzu
wirklich nur eine Handvoll Codezeilen erforderlich sind. Die make-Funktion
des RssMaker-Moduls erledigt alles wesentliche: Der url-Parameter
legt den URL zur Nachrichtenseite fest, auf der die Schlagzeilen mit den
zugehörigen Links stehen. output gibt den Namen der entstehenden
RSS-Datei an. title ist der später im News-Aggregator angezeigte
Titel des Feeds.
Die mit filter angegebene anonyme Subroutine wird von RssMaker
pro entdecktem Link aufgerufen. Jedes Mal
schiebt RssMaker zwei Parameter hinein: Den URL des Links und
den zugehörigen Text. Mit diesen Informationen kann die Subroutine
nun bestimmen, ob der Link eine Schlagzeile ist, die ins Feed aufgenommen
wird oder nicht. Gibt der Filter 1 zurück, wird der Link ins Feed
übernommen, bei 0 nicht.
Im Fall der USA-Rundbriefseite prüft rb2rss einfach,
ob der URL mit rundbrief#\d+ endet, denn das sind die dort voherrschenden
Konventionen für die Zwischenüberschriften. Das war's schon -- fertig
ist das RSS-Feed.
Als zweites, etwas komplexeres Beispiel dient die Startseite des Online- Auftritts der Bildzeitung auf bild.de -- es ist nur als Anschauungsbeispiel zu verstehen, denn wie gesagt existiert seit neuestem [2].
Unter dem angegebenen URL finden sich eine Reihe von Links, die allerdings
mit Javascript verziert sind. bild2rss prüft einfach, ob der
URL das Pattern javascript enthält und parst dann hart aber
herzlich den darin enthaltenen http://...-URL heraus.
Wenn jemand in Perl einen Parameter in eine Subroutine hineinreicht, kann
man auf diesen nicht nur lesend sondern auch schreibend einwirken:
Setzt man $_[0] in der Funktion
auf einen neuen Wert, hat ein Aufruf von
filter($url, $text) für $url im Hauptprogramm einen (vielleicht
unerwarteten) Nebeneffekt, denn der Variablen wird tatsächlich der
neue Wert zugewiesen.
Diesen Hackentrick nutzt die filter-Funktion in bild2rss, um
den URL zu manipulieren, bevor er ins Feed wandert. Der zweite Parameter,
der dem URL im HTML zugewiesene Linktext, wird ebenfalls manipuliert: Zeile
31 wirft alle Sonderzeichen raus, die das entstehende XML verhunzen könnten.
Als Aufnahmekriterium in bild2rss
in das Feed dient der Test in Zeile 32, der einfach
nachsieht, ob der URL die Zeichenfolge BTO enthält -- das scheint allen
auf der Startseite angezeigten Schlagzeilen gemein zu sein.
Services wie Blogline (www.blogline.com) betreiben Web-Applikationen,
die registrierten Nutzern erlauben, Feeds zu abonnieren und deren
Änderungen aktiv zu verfolgen. Als lokal laufende Applikation
empfehle ich Amphetadesk ([3]),
ein Perl-Skript, das auf dem heimischen Rechner als HTTP-Server
läuft und in einem darauf gerichteten Browser eine schöne Übersicht
aller News-würdigen Schlagzeilen anzeigt (Abbildung 1).
Wer prüfen will, ob eine erzeugte RSS-Datei den strengen Vorschriften des Standards entspricht, kann sie Online validieren lassen:
http://feeds.archive.org/validator/
bietet einen kostenlosen Service, der dies in Echtzeit ausführt und bei Erfolg gleich ein formschönes Siegel anbietet (Abbildung 2).
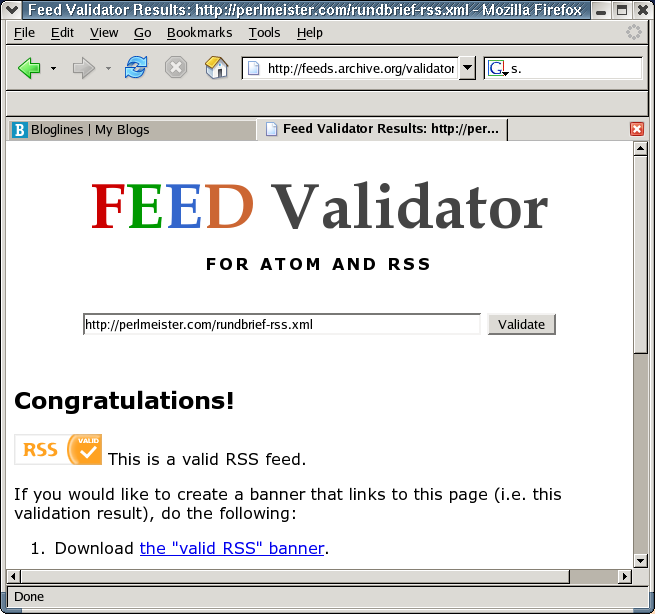 |
| Abbildung 2: Der RSS-Validierer auf feeds.archive.org |
RssMaker.pm nutzt Log4perl im easy-Modus für's Debuggen,
LWP::UserAgent zum Einholen von URLs und XML:RSS zum
Erstellen der RSS-Datei. decode_entities aus HTML::Entities
dekodiert HTML-Escape-Sequenzen wie ü. Die Linkextraktion
in RssMaker.pm erledigt die Funktion exlinks mit
HTML::TreeBuilder. as_trimmed_text() fieselt den Text aus
den gefundenen href-Ankern hervor.
Der RSS-Standard wird voraussichtlich bald von einem neuen, Atom genannt,
abgelöst werden. Die entsprechenden Gremien sind bereits zugange.
Falls irgendwann die unter [7] aufgelisteten Atom-kompatiblen
Clients eine kritische Masse erreichen, wird wohl auch ein
mit RssMaker vergleichbares AtomMaker-Modul vom CPAN erhältlich
sein, das intern das bereits verfügbare XML::Atom-Modul nutzt.
Momentan unterstützen viele populäre Clients das Atom-Format
noch nicht und einige der aufgerüsteten sind extrem buggy.
Eine kurze Ausführung über Atom
in Buchform findet sich in [4]. [5] zeigt ein einfaches Tutorial.
Die von RssMaker.pm geforderten Module sind allesamt vom CPAN
erhältlich. Scraper-Skripts wie rb2rss sollten als Cronjob laufen,
typischerweise einmal am Tag und die entstehende RSS-Datei
auf dem Intranet ablegen, denn das Publizieren von RSS-Dateien
zusammen mit öffentlichem Deep-Linking könnte rechtliche Probleme
aufwerfen.
Während der Debug-Phase ist es hilfreich, die Log4perl-Einstellung des
Skripts auf $DEBUG zu setzen, um am Terminal zu verfolgen, wie
das Einholen, die Link-Extraktion und das Erstellen des RSS-Feeds verläuft.
Im Produktionsbetrieb kann dann mit $ERROR alles überflüssige
ausgeblendet werden, damit der Cronjob keine unnötigen Mails aussendet.
 |
| Abbildung 3: Das Perlmeister-Newsfeed in Bloglines |
001 ###########################################
002 package RssMaker;
003 ###########################################
004 # Mike Schilli, 2004 (m@perlmeister.com)
005 ###########################################
006 use warnings;
007 use strict;
008
009 use LWP::UserAgent;
010 use HTTP::Request::Common;
011 use XML::RSS;
012 use HTML::Entities qw(decode_entities);
013 use URI::URL;
014 use HTTP::Date;
015 use DateTime;
016 use HTML::TreeBuilder;
017 use Log::Log4perl qw(:easy);
018
019 ###########################################
020 sub make {
021 ###########################################
022 my(%o) = @_;
023
024 $o{url} || LOGDIE "url missing";
025 $o{title} || LOGDIE "title missing";
026 $o{output} ||= "out.rdf";
027 $o{filter} ||= sub { 1 };
028 $o{encoding} ||= 'utf-8';
029
030 my $ua = LWP::UserAgent->new();
031
032 INFO "Fetching $o{url}";
033 my $resp = $ua->request(GET $o{url});
034
035 LOGDIE "Fetching $o{url} failed" if
036 $resp->is_error();
037
038 my $http_time =
039 $resp->header('last-modified');
040 INFO "Last modified: $http_time";
041
042 my $mtime = str2time($http_time);
043 my $isotime = DateTime->from_epoch(
044 epoch => $mtime);
045 DEBUG "Last modified: $isotime";
046
047 my $rss = XML::RSS->new(
048 encoding => $o{encoding});
049
050 $rss->channel(
051 title => $o{title},
052 link => $o{url},
053 dc => { date => $isotime . "Z"},
054 );
055
056 foreach(exlinks($resp->content(),
057 $o{url})) {
058
059 my($lurl, $text) = @$_;
060
061 $text = decode_entities($text);
062
063 if($o{filter}->($lurl, $text)) {
064 INFO "Adding rss entry: $text $lurl";
065 $rss->add_item(
066 title => $text,
067 link => $lurl,
068 );
069 }
070 }
071
072 INFO "Saving output in $o{output}";
073 $rss->save($o{output}) or
074 die "Cannot write to $o{output}";
075 }
076
077 ###########################################
078 sub exlinks {
079 ###########################################
080 my($html, $base_url) = @_;
081
082 my @links = ();
083
084 my $tree = HTML::TreeBuilder->new();
085
086 $tree->parse($html) or return ();
087
088 for(@{$tree->extract_links('a')}) {
089 my($link, $element, $attr,
090 $tag) = @$_;
091
092 next unless $attr eq "href";
093
094 my $uri = URI->new_abs($link,
095 $base_url);
096 next unless
097 length $element->as_trimmed_text();
098
099 push @links,
100 [URI->new_abs($link, $base_url),
101 $element->as_trimmed_text()];
102 }
103
104 return @links;
105 }
106
107 1;
01 #!/usr/bin/perl
02 ###########################################
03 # rb2rss - Rundbrief to RSS feed
04 # Mike Schilli, 2004 (m@perlmeister.com)
05 ###########################################
06 use warnings;
07 use strict;
08
09 use RssMaker;
10 use Log::Log4perl qw(:easy);
11 Log::Log4perl->easy_init($INFO);
12
13 RssMaker::make(
14 url =>
15 "http://perlmeister.com/rundbrief",
16 title => "Perlmeister",
17 filter => sub {
18 my($url, $text) = @_;
19 $url =~ /rundbrief#\d+$/;
20 },
21 encoding => 'iso-8859-1',
22 output => 'rundbrief.rss',
23 );
01 #!/usr/bin/perl
02 ###########################################
03 # bild2rss - bild.de as *.rss
04 # Mike Schilli, 2004 (m@perlmeister.com)
05 ###########################################
06 use warnings;
07 use strict;
08
09 use RssMaker;
10 use Log::Log4perl qw(:easy);
11
12 Log::Log4perl->easy_init($INFO);
13
14 my $url = "http://www.bild.t-online.de/" .
15 "BTO/Startseite/StartBuehne," .
16 "templateId=renderKomplett.html";
17
18 RssMaker::make(
19 url => $url,
20 title => "Bildzeitung",
21 filter => sub {
22 my($link, $text) = @_;
23 if($link =~ /javascript/) {
24 if($link =~ /'(http:\/.*?)'/) {
25 $link = $1;
26 $_[0] = $link;
27 } else {
28 return 0;
29 }
30 }
31 $_[1] =~ s/[^[:print:]äöüÄÖÜß]//g;
32 $link =~ m#BTO#i ? 1 : 0;
33 },
34 output => "bild.rss",
35 encoding => "iso-8859-1");
 |
Michael Schilliarbeitet als Software-Engineer bei Yahoo! in Sunnyvale, Kalifornien. Er hat "Goto Perl 5" (deutsch) und "Perl Power" (englisch) für Addison-Wesley geschrieben und ist unter mschilli@perlmeister.com zu erreichen. Seine Homepage: http://perlmeister.com. |