
Wenn heute irgendwo Daten bereitstehen, dann oft in XML. Perl bietet eine Unzahl von Methoden, XML zu bearbeiten. Um die Auswahl des am besten geeigneten Verfahrens zu erleichtern, stellt der Perl-Snapshot heute die gängisten mit ihren Vor- und Nachteilen vor.
Das heute untersuchte Beispiel-XML in Abbildung 1 enthält zwei
Datensätze vom Typ <cd> in einem <result>-Tag.
Die <cd>-Datensätze enthalten wiederum Tags für
<artists> und <title> einer CD. <artists>
wiederum führt ein oder mehrere <artist>-Tags.
| |
| Abbildung 1: XML-Daten |
 |
| Abbildung 2: XML-Daten in XML::Simple |
Am einfachsten parst sich XML in Perl mit XML::Simple vom CPAN. Es
exportiert die Funktion XMLin, die eine Datei oder einen String
mit XML-Daten einsaugt und als Datenstruktur in Perl ablegt:
use XML::Simple;
my $ref = XMLin("data.xml");
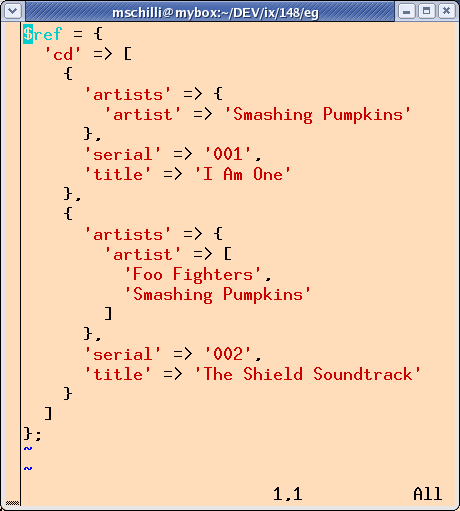
Abbildung 2 zeigt einen Dump der resultierenden Datenstruktur in $ref:
Zwei Dinge fallen auf: Abhängig davon, ob ein oder zwei Künstler
in <artists> stehen, ist die resultierende Datenstruktur
entweder ein Skalar oder ein Array. Das erschwert später die
Arbeit mit der Datenstruktur. Mit
der Option ForceArray lässt sich jedoch festlegen, dass ein Feld immer
als Array dargestellt wird. Der Aufruf
XMLin("data.xml",
ForceArray => ['artist']);
stellt sicher, dass
$ref->{cd}->[0]->{artists}->{artist} ebenfalls
eine Arrayreferenz zurückgibt, obwohl dort nur ein einziger
Interpret steht. Weiterhin ist
->{artists}->{artist} etwas umständlich zu schreiben,
da ->{artists}
außer ->{artist} keine weiteren Unterelemente enthält.
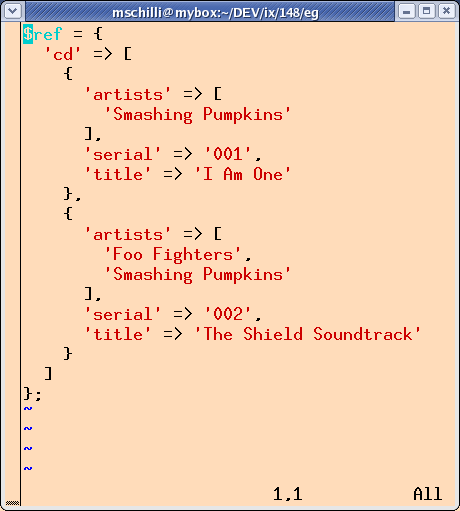
XML::Simple bietet mit der GroupTags-Option die Möglichkeit,
Hierarchien kollabieren zu lassen. Der Aufruf
XMLin("data.xml",
ForceArray => ['artist'],
GroupTags =>
{'artists' => 'artist'});
erzeugt die Datenstruktur in Abbildung 3, die schon sehr einfach zu
handhaben ist. Aufgaben wie ``Finde alle Seriennummern'' lassen sich
nun einfach mit for-Schleifen lösen:
for my $cd (@{$ref->{cd}}) {
print $cd->{serial}, "\n";
}
Dass XML::Simple das gesamte XML in den Hauptspeicher einliest ist nicht nur praktisch, sondern kann auch zum Problem werden: Bei riesigen XML-Dateien ist das nicht effizient oder schlichtweg unmöglich.
 |
| Abbildung 3: XML-Daten in XML::Simple mit GroupTags |
Wer auf konzise Notationen steht, wird XPath lieben, um durch
den XML-Dschungel zu navigieren. Das Modul XML::LibXML vom CPAN
hängt sich an die libxml2-Bibliothek des Gnome-Projektes an
und bietet über die findnodes-Methode auch die Möglichkeit,
per XPath-Notation auf XML-Elemente zuzugreifen.
Um zum Beispiel den Textinhalt aller <title>-Elemente
zutage zu fördern, genügt die XPath-Notation
/result/cd/title/text()
die mit ``/'' an der Dokumentenwurzel anfängt, in die
<results>,
<cd>
und <title>-Elemente hinabsteigt und mit text() deren
Textinhalt zurückgibt. Alternativ geht es auch mit
//title/text()
denn so stöbert XPath einfach alle <title>-Elemente
in beliebiger Tiefe auf.
Listing xptitles zeigt, dass die Methode findnodes()
eine Reihe von Text-Objekten zurückgibt, deren Methode toString()
schließlich den Titeltext liefert.
01 #!/usr/bin/perl -w
02 use strict;
03 use XML::LibXML;
04
05 my $x = XML::LibXML->new() or
06 die "new failed";
07
08 my $d = $x->parse_file("data.xml") or
09 die "parse failed";
10
11 my $titles =
12 "/result/cd/title/text()";
13
14 for my $title ($d->findnodes($titles)) {
15 print $title->toString(), "\n";
16 }
Aber mit XPath lassen sich auch komplexere Aufgaben lösen:
Listing xpserial fieselt die Seriennummern aller CDs heraus,
die einen <artist>-Tag mit dem Inhalt "Foo Fighters"
aufweisen. Hierzu steigt der XPath
/result/cd/artists/artist[.="Foo Fighters"]/../../@serial
zunächst bis zu den <artist>-Tags hinab, prüft dann
mit dem Prädikat
[.="Foo Fighters"]
ob deren Inhalt ``Foo Fighters'' ist. Das in eckige Klammern
eingeschlossene Prädikat referenziert mit ``.'' den aktuellen
Knoten im Pfad und prüft mit ``='', ob der Stringwert des Knotens
mit dem String ``Foo Fighters'' identisch ist.
Ist dies der Fall, fährt XPath mit ``../..'' anschließend
zwei Etagen hoch. Auf dieser Ebene ist
das <cd>-Tag, dessen Parameter serial es
mittels @serial ausliest und zurückgibt.
Listing xpserial muss dann nur noch die value()-Methode
des zurückgelieferten Objekts aufrufen, um den Wert
des Parameters, also die Seriennummer zu erhalten.
01 #!/usr/bin/perl -w
02 use strict;
03 use XML::LibXML;
04
05 my $x = XML::LibXML->new() or
06 die "new failed";
07
08 my $d = $x->parse_file("data.xml") or
09 die "parse failed";
10
11 my $serials = q{
12 /result/cd/artists/
13 artist[.="Foo Fighters"]/
14 ../../@serial
15 };
16
17 for my $serial ($d->findnodes($serials)) {
18 print $serial->value(), "\n";
19 }
XPath erlaubt bündige Formulierungen, funktioniert aber etwas nicht auf Anhieb, kann sich die Entwicklungsarbeit hinziehen. In einer limitierten Umgebung wie XLST kann das zum Problem werden, aber Perl bügelt das rasch aus: Dort lassen sich schnelle XPath-Hacks mit solider Programmlogik und superben Debugmöglichkeiten kombinieren.
Einen eher klassischen Parser implementiert das Modul XML::Parser. Er beißt sich Tag für Tag durch ein XML-Dokument und ruft bei eintretenden Bedingungen benutzerdefinierte Callbacks auf. Um wiederum die Seriennummern aller CDs zu finden, deren Interpret ``Foo Fighter'' ist, muss der Code auf dem Weg in die Tiefen einer XML-Struktur den Status festhalten, um ihn später für Entscheidungen oder Ausgaben heranzuziehen.
Wie Listing xmlparse zeigt, erwartet der XML::Parser-Konstruktor
new() callbacks für Ereignisse wie Start (der Parser trifft
auf ein öffnendes XML-Tag) oder Char (der Parser findet
von Markup eingeschlossenen Text).
Der Parser ruft die ab Zeile 21 definierte Funktion start() mit
einer Referenz auf den Parser, dem Tagnamen und einer Key/Value-Liste
von Attributen auf, falls er auf ein öffnendes Tag wie
<cd serial="001"> stößt. Im vorliegenden Fall erhält
die Funktion start()
als zweiten Parameter den String "cd" und als dritten und
vierten "serial" und "001".
Der ab Zeile 33 definierte Callback text() hingegen erhält von
XML::Parser bei gefundenen Textstücken zwei Parameter:
eine Referenz auf den Parser und einen String, in dem der
gefundene Text steht. Damit der Parser weiß, dass ein gefundenes
Textstück der Name eines Interpreten ist, muss er prüfen, ob
er sich gerade innerhalb eines <artist>-Tags befindet,
und das weiss er nur, weil die globale Variable $is_artist vorher
vom start-Callback entsprechend gesetzt wurde. Und auch die
Seriennummer, die vorher von start im serial-Attribut des
<cd>-Tags gefunden wurde, rettet die Variable $serial
in den Aufruf von text() hinüber, damit die print-Funktion dort
die Seriennummer der gegenwärtig untersuchten CD ausgeben kann.
Dieses Verfahren setzt natürlich voraus, dass jede CD ein
<serial>-Attribut führt, aber das lässt sich in einem
vorausgehenden Validierungsschritt zum Beispiel mit einer DTD
sicherstellen.
01 #!/usr/bin/perl -w
02 use strict;
03
04 use XML::Parser;
05
06 my $p = XML::Parser->new();
07 $p->setHandlers(
08 Start => \&start,
09 Char => \&text,
10 );
11 $p->parsefile("data.xml");
12
13 my $serial;
14 my $is_artist;
15
16 ###########################################
17 sub start {
18 ###########################################
19 my($p, $tag, %attrs) = @_;
20
21 if($tag eq "cd") {
22 $serial = $attrs{serial};
23 }
24
25 $is_artist = ($tag eq "artist");
26 }
27
28 ###########################################
29 sub text {
30 ###########################################
31 my($p, $text) = @_;
32
33 if($is_artist and
34 $text eq "Foo Fighters") {
35 print "$serial\n";
36 }
37 }
Das Modul XML::Parser wird meist nicht direkt genutzt, sondern als Basisklasse von selbst gezimmerten Klassen. Selbst das anfangs besprochene XML::Simple greift -- je nach Installationsumgebung -- darauf zurück und lässt sich mit
$XML::Simple::PREFERRED_PARSER = "XML::Parser";
dazu überreden. Auf problematischen Plattformen ist ``XML::SAX::PurePerl'', ein weiterer Parser vom CPAN, eine akzeptable Wahl, wenn auch nicht die schnellste. Er lässt sich auch ohne C-Compiler installieren.
Die Installation von XML::Parser kann sich nämlich
etwas hinziehen, denn es setzt einen ordnungsgemäß installierten
expat-Parser voraus.
Wer sich diese Arbeit sparen will, missbraucht
einfach das Modul HTML::Parser für XML-Zwecke. Seine Syntax ist nur
geringfügig anders und mit dem gesetzten xml_mode schaltet es von
schlampiger HTML-Interpretation in die strenge XML-Welt um.
In Listing htmlparse fällt auf, dass der
HTML::Parser-Konstruktor
eine geringfüg andere Syntax akzeptiert als
XML::Parser. Nachdem die Version der genutzten API (3) festgelegt
ist, setzen die Parameter start_h und text_h die Callbacks für
öffnende Tags und Textstücke außerhalb des XML-Markups. Weiter legt
der Konstruktor fest, welche Parameter der Parser an die Callbacks
weitergibt: start() erhält den Namen des aufgehenden Tags und eine
Attributliste (diesmal als Referenz auf einen Array) und die
Funktion text() erhält lediglich das gefundene Textstück.
01 #!/usr/bin/perl -w
02 use strict;
03 use HTML::Parser;
04
05 my $p = HTML::Parser->new(
06 api_version => 3,
07 start_h => [\&start, "tagname, attr"],
08 text_h => [\&text, "dtext" ],
09 xml_mode => 1,
10 );
11
12 $p->parse_file("data.xml") or
13 die "Cannot parse";
14
15 my $serial;
16 my $artist;
17
18 ###########################################
19 sub start {
20 ###########################################
21 my($tag, $attrs) = @_;
22
23 if($tag eq "cd") {
24 $serial = $attrs->{serial};
25 }
26
27 $artist = ($tag eq "artist");
28 }
29
30 ###########################################
31 sub text {
32 ###########################################
33 my($text) = @_;
34
35 if($artist and
36 $text eq "Foo Fighters") {
37 print "$serial\n";
38 }
39 }
Eine erstaunlich effektive Abbildung von XML-Datenstrukturen in Perl-Code bietet XML::Twig von Michel Rodriguez. Es verarbeitet auch monströse Dokumente, bei denen XML::Simple längst ausgestiegen wäre, da sie nicht vollständig in den Speicher eingelesen werden, sondern nur soviel wie notwendig.
XML::Twig bietet so viele verschiedene Methoden, durch XML zu
navigieren, dass es schwer fällt, die am besten geeignete zu finden.
Listing twig zeigt den Aufruf des Konstruktors XML::Twig::new
mit dem Parameter Twighandlers, der dem XML-Pfad
/result/cd/artists/artist den ab Zeile 18 definierten Handler
artist zuweist. Sobald XML::Twig beim Parsen des XML-Dokuments auf
ein <artist>-Tag, ruft es die Funktion artist mit
zwei Parametern auf: dem XML::Twig-Objekt und dem XML::Twig::Elt-Objekt
(Elt steht wohl für Element) stößt,
das den XML-Baumknoten repräsentiert, an dem das <artist>-Tag
hängt.
Die Methode text() des Artist-Objektes liefert den Text
zwischen dem öffnenden und dem schließenden
<artist>-Tag. Steht dort ``Foo Fighters'', navigiert
Zeile 24 zum darüberliegenden <cd>-Tag, indem es zweimal
die parent()-Methode ausführt. Das so gefundene CD-Objekt
kann dann mit der Methode att() nach dem Wert des Attributs
serial gefragt und der gefundene Wert ausgegeben werden.
Jedesmal, wenn wieder ein Artist-Tag abgearbeitet wurde, ruft
die Funktion artist() die Methode purge() des
XML-Twig-Objekts auf, um ihm mitzuteilen, dass der Baum bis zum
aktuell bearbeiteten Tag nicht mehr gebraucht wird und dieser Teil
deswegen zur Freigabe ansteht. XML::Twig ist so intelligent, direkte Eltern
des gerade bearbeiteten Tags nicht wegzuputzen, bereits
bearbeitete Geschwister fallen hingegen der Müllabfuhr zum Opfer.
Bei einem kurzen XML-Stück ist dieses Speichermanagement witzlos, bei einem
riesigen Dokument kann es aber des Ausschlag geben, ob ein Programm noch
funktioniert oder nicht.
01 #!/usr/bin/perl -w
02 use strict;
03 use XML::Twig;
04
05 my $twig= XML::Twig->new(
06 TwigHandlers => {
07 "/result/cd/artists/artist" => \&artist
08 }
09 );
10
11 $twig->parsefile("data.xml");
12
13 ###########################################
14 sub artist {
15 ###########################################
16 my($t, $artist)= @_;
17
18 if($artist->text() eq "Foo Fighters") {
19 my $cd =
20 $artist->parent()->parent();
21
22 print $cd->att('serial'), "\n";
23 }
24 # Release memory of processed tree
25 # up to here
26 $t->purge();
27 }
XML::Twig navigiert aber nicht nur elegant in einem XML-Dokument
herum. Ein Skript kann während des Navigierens Tags umbenennen, den Baum
mit Methodenaufrufen dynamisch verändern oder sogar Teile abstoßen, um
Speicher zu sparen. Um zum Beispiel im vorliegenden
XML-Dokument aus den cd-Tags die serial='xxx'-Attribute der
Form
<cd serial="xxx">
...
</cd>
in Unterelemente der Form
<cd>
<id>xxx</id>
...
</cd>
umzuwandeln und gleichzeitig die Artist-Informationen zu tilgen,
holt das Skript twigfilter zunächst mit root() das Wurzelobjekt
(<results>) hervor. Anschließend liefert die
Methode children() alle Kindobjekte des Wurzelobjekts, also
die cd-Elemente. Deren serial-Attribute
transformiert die Methode att_to_field() in Feldelemente mit
dem Namen id. Anschließend holt first_child() das erste
(und einzige) artist-Element hervor, dessen delete()-Methode
den Knoten selbst zerstört und aus dem Baum ausklinkt.
Schließlich benennt die set_gi()-Methode (gi steht für Generic
Identifier) des cd-Objekts
das gerade durchlaufene <cd<gt>-Tag in (<Compact Disc<gt> um.
Abbildung 4
zeigt das Ergebnis.
Wegen des auf ``indent'' gesetzten PrettyPrint-Parameters im Konstruktor
gibt die in Zeile 22 aufgerufene Methode print() den Ergebnisbaum
schön eingerückt aus.
Mit XML::Twig lassen sich unglaublich kompakte Programme schreiben,
es erfordert lediglich etwas Übung, die richtigen Methoden zu finden.
01 #!/usr/bin/perl -w
02 use strict;
03 use XML::Twig;
04
05 my $twig= XML::Twig->new(
06 PrettyPrint => "indented");
07
08 $twig->parsefile("data.xml") or
09 die "Parse error";
10
11 my $root = $twig->root();
12
13 for my $cd ($root->children('cd')) {
14 $cd->att_to_field('serial', 'id');
15 $cd->first_child('artists')->delete();
16 $cd->set_gi("Compact Disc");
17 }
18
19 $root->print();
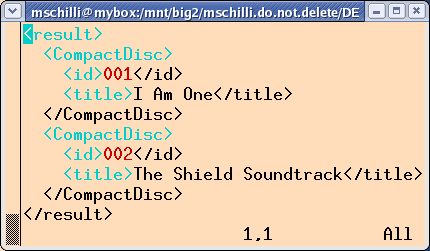 |
| Abbildung 4: twigfilter gibt das modifizierte XML aus. |
Wer gerne interaktiv herumprobiert, für den gibt es die
xsh-Shell des Moduls XML::XSH. Mit xsh aufgerufen, öffnet
sich ein Kommandointerpreter, mit dem man XML-Dokumente von der
Festplatte lesen oder aus dem Web holen kann. Anschließend lassen
sich beliebig komplexe XPath-Abfragen abfeuern. Die Ergebnisse
liegen sofort als Kommandoausgaben vor und erlauben es, die Queries
fortlaufend zu verfeinern.
Abbildung 5 zeigt, wie der Shell-Benutzer zunächst mit
open docA = "data.xml"
das XML-Dokument von der Platte einliest und dann mit dem Kommando
ls eine XPath-Abfrage abfeuert, deren Ergebnis, eine einzelne
Seriennummer mit serial='002', angezeigt wird.
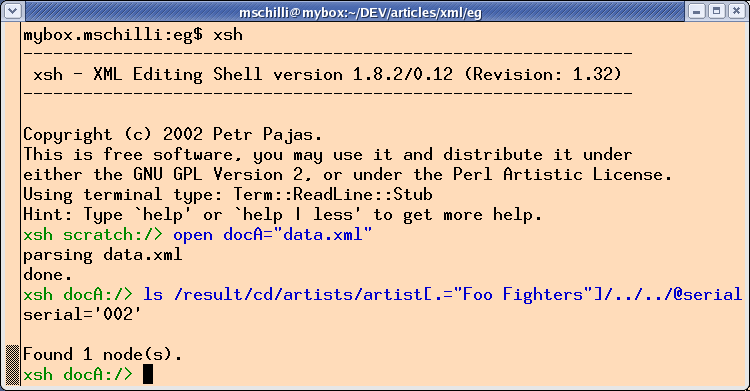 |
| Abbildung 5: XPath-Abfragen in der interaktiven xsh-Shell |
Dies waren nur einige ausgewählte Beispiele aus der Vielzahl verfügbarer XML-Module vom CPAN. XML::XPath, XML::DOM, XML::Mini, XML::Grove sind weitere Möglichkeiten, aus dem schier unergründlichen Brunnen zu schöpfen. Jedem das seine, nicht jedem das gleiche!
 |
Michael Schilliarbeitet als Software-Engineer bei Yahoo! in Sunnyvale, Kalifornien. Er hat "Goto Perl 5" (deutsch) und "Perl Power" (englisch) für Addison-Wesley geschrieben und ist unter mschilli@perlmeister.com zu erreichen. Seine Homepage: http://perlmeister.com. |