Selbst hochrangige Wissenschaftler begehen in ihren Publikationen reihenweise Leichtsinnsfehler, die jeder erkennen sollte, der sich je mit statistischen Methoden befasst hat. Simulationen in Perl fühlen ihnen auf den Zahn.
Drückt man einem Mensch-Ärgere-Dich-Nicht-Spieler einen neuen Würfel in die Hand, wird dieser stutzig werden, und ungläubig die Seitenflächen kontrollieren, falls seine ersten drei Würfe jeweils nur eine Eins hervorbringen. Zu welchem Zeitpunkt aber kann man wissenschaftlich nachweisen, dass mit einem Würfel etwas nicht stimmt, er also nicht alle Punktezahlen von eins bis sechs gleichmäßig verteilt liefert? Nach fünf Würfen, die alle Einsen zeigen? Nach 10?
Letzendlich spielen in jedes Experiment Fluktuationen hinein. Es ist eine Frage der Wahrscheinlichkeit, was am Ende dabei exakt herauskommt, und nur die grobe Richtung ist wissenschaftlich relevant. Ein unglücklicher Brettspieler kann auch mit einem regulären Würfel durchaus dreimal hintereinander eine Eins werfen. Solche Zufälle kommen zwar selten vor, aber es gibt sie, und deswegen wäre anzuraten, nicht schon aus derart wenigen Durchläufen in einem Experiment Folgerungen über den Würfel abzuleiten, voreilige und unrichtige Schlüsse wären die Folge.
Der Wissenschaftler definiert deshalb für das Experiment eine sogenannte Null-Hypothese (zum Beispiel "Der Würfel ist fair" oder "Das Medikament zeigt keine Wirkung"), die aufgrund des Testergebnisses später entweder bestätigt oder verworfen wird. Den Irrtum, eine richtige Nullhypothese zu verwerfen, nennt der Statistiker einen "Fehler erster Art". Experimente legen vorab fest, mit welcher maximalen Wahrscheinlichkeit sie das Auftretens dieses Fehlers gerade noch akzeptieren, dieser Wert nennt sich Signifikanzniveau des Experiments.
| |
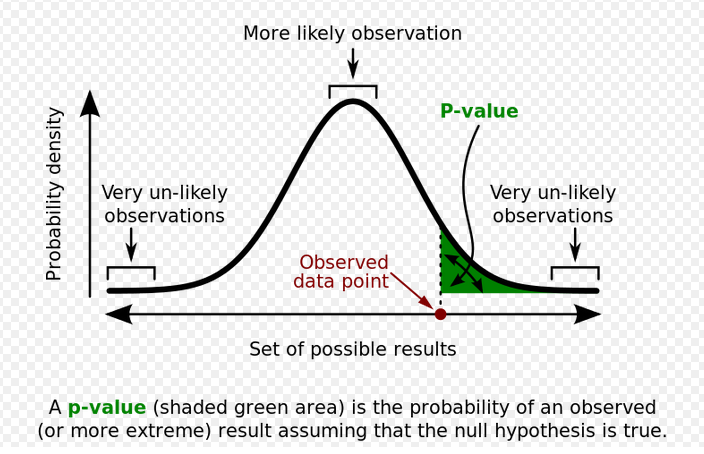
| Abbildung 1: Der p-Wert gibt die Wahrscheinlichkeit an, mit der das Experiment noch "extremere" Werte als die gefundenen zeigt (Quelle: Wikipedia [4]). |
Der sogenannte p-Wert [4] ist ein Wahrscheinlichkeitswert zwischen 0 und 1, der sich bei der Durchführung des Experiments bestimmt und der angibt, wie wahrscheinlich es ist, das gefundene oder ein noch "extremeres" Ergebnis zu erhalten. Je kleiner der p-Wert, desto "signifikanter" war der Test und die Nullhypothese ist mit hoher Wahrscheinlichkeit falsch. Zeigt eine 20 Mal geworfene Münze zum Beispiel 14 mal "Kopf" (10 Mal wären zu erwarten), ist der p-Wert mit 0.115 laut [4] noch gut über dem in wissenschaftlichen Kreisen üblichen Schwellwert von 5% (0.05). Das Experiment kann die Null-Hypothese also guten Gewissens akzeptieren und hat mit maximal 5% Irrtumswahrscheinlichkeit belegt, dass die Münze erwartungsgemäß fällt. Wären bei 20 Würfen nicht nur 14 sondern gleich 15 mal Kopf gekommen, wäre der p-Wert mit 0.041 unter die 5%-Marke abgesackt und die Null-Hypothese sowie die Qualität der Münze auf einmal fragwürdig erschienen.
Das Perl-Skript in Listing 1 wirft eine faire Münze mit den Seiten
"H" ("heads", englisch für "Kopf") und
"T" ("tails", englisch für die "Zahl"-Seite einer Münze)
insgesamt 1000 mal und rechnet dann zusammen, wie oft der Kopf oben lag.
Daraus erechnet die Funktion p_value() ab Zeile 23 dann den p-Wert
und die Ausgabe des Skripts hilft bei der Entscheidung, ob die Münze
gleichmäßig fiel oder möglicherwiese eine Anomalie vorliegt:
$ ./coin-toss Rounds: 1000 Tails: 507 p-value: 0.182979
Bei 1000 Würfen kam also 507 mal Kopf und der p-Wert beträgt 0.18, liegt solide über dem Schwellwert von 5% und damit kann die Null-Hypothese guten Gewissens akzeptiert werden.
01 #!/usr/local/bin/perl -w
02 use strict;
03 use Math::BigFloat;
04
05 my @sides = qw( H T );
06 my $rounds = 1000;
07 my $tails = 0;
08
09 for ( 1 .. $rounds ) {
10 my $side = $sides[ rand scalar @sides ];
11
12 if( $side eq "T" ) {
13 $tails++;
14 }
15 }
16
17 printf "Rounds: $rounds\n";
18 printf "Tails: $tails\n";
19 printf "p-value: %f\n",
20 p_value( $tails, $rounds/2, $rounds );
21
22 ###########################################
23 sub p_value {
24 ###########################################
25 my( $tails, $expect, $rounds ) = @_;
26
27 my @vals = ( $tails < $expect ?
28 ( 1 .. $tails ) :
29 ( $tails .. $rounds ) );
30
31 my $sum = Math::BigFloat->new( 0 );
32
33 for my $val ( @vals ) {
34 my $nok =
35 Math::BigFloat->new( $rounds );
36 $nok->bnok( $val );
37 $sum->badd( $nok );
38 }
39
40 my $total = Math::BigFloat->new( 2 );
41 $total->bpow( $rounds );
42
43 return 2 *
44 $sum->bdiv( $total )->numify();
45 }
Das Skript wählt aus dem Array @sides in jeder der 1000 Runden zufällig eines
der beiden Symbole "H" oder "T" aus und legt damit fest, ob die Münze Kopf
oder Zahl zeigt. Im letzteren Fall erhöht sie den Zähler $tails in Zeile X um 1
zur späteren Auswertung.
Wie berechnet sich nun der p-Wert? Kommt im Experiment bei 10 Würfen 7 mal Kopf, wäre ein noch extremeres Ergebnis zweifellos wenn 8, 9 oder gar zehnmal Kopf gekommen wären. Da die Münze symmetrisch ist und auch 8, 9 oder zehnmal Zahl "extremer" wären, bezieht der p-Wert diese ebenfalls mit ein. Die Wahrscheinlichkeit, dass sich bei einem binominalverteilten Experiment with einem n-maligen Münzwurf k mal "Kopf" oder "Zahl" zeigt, berechnet sich aus dem Binominalkoeffizienten (n k), dividiert durch die Gesamtzahl der Kombinationen, also 2**n.
Die Funktion p_value() ab Zeile 23 nutzt zur Berechnung des Binominalkoeffizienten
sowie der anschließenden Division das CPAN-Modul Math::BigFloat, denn bei den dazu
erforderlichen Schritten ergeben
sich bei längeren Experimenten Zahlenwerte, die die Floating-Point-Kapazität der
meisten Rechner weit übersteigen. Math::BigFloat hingegen rechnet beliebig genau,
auch wenn Werte mit vielen tausend Stellen entstehen. Den Binominalkoeffizienten
(n k) ermittelt die Methode bnok() in Zeile 36, während Zeile 37 das Teilergebnis
mit badd() aufkumuliert. Liegt das Ergebnis unter dem Erwartungswert (also
zum Beispiel 10 bei 20 Würfen), sucht der Algorithmus extremere Werte links davon
(also aufsteigend von 1, 2, bis zum im Experiment gesehenen Wert). Liegt der
Experimentwert hingegen auf der rechten Seite der Glockenkurve, zählt er von diesem
Wert bis zum Maximalwert hoch. In beiden Fällen multipliziert Zeile 43 wegen
der Symmetrie des Experiments (Kopf oder Zahl sind austauschbar) noch mal zwei.
Um zu simulieren, was mit einer unegalen Münze passieren würde, die etwas häufiger Zahl wie Kopf zeigt, fügt der Experimentierfreudige in Zeile 5 von Listing 1 einige weitere Münzenseiten ein:
my @sides = qw( H H H T T T T );
Von sieben Würfen zeigt die Münze dann im Schnitt dreimal Kopf ("H") und viermal Zahl ("T"), das Skript rechnet entsprechend (mit zufälligen Abweichungen) etwa folgenden p-Wert aus:
$ Rounds: 1000 Tails: 565 p-value: 0.000351
Der p-Wert liegt also bei etwa 0.04% und damit weit unter der vorgegebenen 5%-Grenze für den Signifikanzwert. Er bringt die Nullhypothese, dass die Münze mit gleicher Wahrscheinlichkeit auf beide Seiten fällt, gehörig ins Wanken.
Experimente, die neue Medikamente oder Behandlungsprozeduren auf ihre Wirksamkeit testen, definieren die Nullhypothese als "Das Mittel ist wirkungslos", setzen den Signifikanzwert auf etwa 5% und schlagen dann Alarm, wenn der p-Wert im Experiment darunter absackt, also plötzlich gute Gründe für die Annahme vorliegen, dass die Nullhypothese falsch ist, Das suspekt beäugte Wundermittel zeigt in diesem Fall mit guter Wahrscheinlichkeit tatsächliche Behandlungserfolge.
Allerdings ist es laut [2] gang und gäbe, dass Studien diesen Signifikanzwert abschließend falsch bewerten und der Patient sich falsche Hoffnungen macht oder grundlos in Panik verfällt. Diese sogenannten Basisratenfehler oder auch Prävalenzfehler ([3]) bestehen darin, die Signifikanz des Tests als dessen Fähigkeit, eine richtige Diagnose an einem zufällig ausgewählten Patienten zu verkaufen, ohne die sogenannte A-priori-Wahrscheinlichkeit in der Anwendung an großen Patientengruppen zu berücksichtigen.
Folgendes Experiment aus [2] zeigt die für viele erstaunliche Abweichung zwischen landläufiger Meinung und exakter Wissenschaft: Eine Mammografie stellt bei Patientinnen mit Brustkrebs mit 90%-iger Wahrscheinlichkeit die richtige Diagnose. Allerdings stellt der Test bei etwa 7% von gesunden Patientinnen ebenfalls die Diagnose Brustkrebs, sodass bei positivem Befund weitere Diagnoseverfahren zur Klärung eingeleitet werden. Nun die Frage: Ist dieser Test dazu geeignet, um die Bevölkerung effektiv auf Brustkrebs zu testen? Falls die Mammografie auf Brustkrebs erkennt, wie hoch ist dann die Wahrscheinlichkeit, dass die zufällig ausgewählte Frau tatsächlich Brustkrebs hat?
Die meisten Leute würden kurz überlegen, dann im Kopf die 7% Fehlerrate von 100% abziehen und bei etwa 93% landen. Aber das ist ist grundfalsch. Was ist das richtige Ergebnis? 70% vielleicht? 50% gar? Die verblüffende Wahrheit: Die Wahrscheinlichkeit, dass eine Mammografie bei einer zufällig ausgewählten Frau richtig auf Brustkrebs erkennt, liegt bei nur etwa 9%.
01 #!/usr/bin/perl -w
02 use strict;
03 use Data::Dumper;
04 use Algorithm::Numerical::Shuffle
05 qw( shuffle );
06
07 my $nof_patients = 1000;
08 my $nof_infects = 8;
09 my $tested_pos = 0;
10 my $tested_corr = 0;
11
12 my @patients = ( 0 ) x $nof_patients;
13
14 infect( \@patients, $nof_infects );
15
16 while( $tested_pos != 100000 ) {
17
18 my $patient =
19 $patients[ rand $nof_patients ];
20 my $result = examine( $patient );
21
22 next if !$result;
23
24 $tested_pos++;
25
26 # diagnosis correct?
27 $tested_corr++ if $patient;
28 }
29
30 printf "Test score: %3.2f%%\n",
31 $tested_corr / $tested_pos * 100.0;
32
33 ###########################################
34 sub examine {
35 ###########################################
36 my( $patient ) = @_;
37
38 my $rand = int rand 100;
39
40 if( $patient ) {
41 # 90% detection rate
42 return $rand < 90 ? 1 : 0;
43 } else {
44 # 7% false positive
45 return $rand < 7 ? 1 : 0;
46 }
47 }
48
49 ###########################################
50 sub infect {
51 ###########################################
52 my( $patients, $howmany ) = @_;
53
54 my @rand_indices =
55 shuffle ( 0 .. $#$patients );
56
57 while( $howmany-- ) {
58 $patients[ shift @rand_indices ] = 1;
59 }
60 }
Wer im Experiment in Gedanken eben bei einer zu hohen Testgenauigkeit angelangt ist, hat den typischen Prävalenzfehler begangen und vergessen, in die Berechnung mit einzubeziehen, dass in der allgemeinen Bevölkerung nur etwa 0.8% der Frauen Brustkrebs haben.
Von 1000 Frauen haben also 992 Frauen keinen Brustkrebs und für die liefert die Mammografie in 7% der Fälle die falsche Diagnose, also bekommen 70 getestete Frauen ein inkorrektes Ergebnis. Von den 8 Frauen mit Brustkrebs diagnostiziert der Test diesen bei 7 korrekt. Das Ergebnis: von 77 Brustkrebsbefunden durch die Mammografie sind nur 7 korrekt, also etwa 9%. Bei dieser geringen Trefferrate ist davon abzuraten, flächendeckend zu testen, sondern nur bestimmte Risikogruppen einzubeziehen, bei denen ein schlechter Test besser ist als gar keiner.
Listing 2 simuliert das Experiment in Perl. In einen Array mit
1000 Frauen, deren Gesundheitszustand zunächst in Zeile 12 mit 0 auf
"ohne Befund" gesetzt wird, bringt die Funktion infect() ab Zeile 50 zufällig
verteilt 8 Einsen ein, simuliert also die 0.8% von Frauen mit Brustkrebs in
der allgemeinen Bevölkerung. Dazu mischt Zeile 55 mit der Funktion shuffle()
aus dem CPAN-Modul Algorithm::Shuffle nach dem Fisher-Yates-Verfahren einen
Array mit Indexnummern des Patientenarrays durch, zieht dann insgesamt
acht heraus und modifiziert den Array an diesen Stellen.
Das Experiment läuft über die while-Schleife in Zeile 16 solange, bis die
Mammografie 100.000 positive Befunde ausgespuckt hat, jeweils eingeleitet
durch die Funktion examine() ab Zeile 34 mit dem (zu Testzwecken) vorab bekannten
Gesundheitszustand der Patientin. Die Diagnose berücksichtigt Fehler erster
(10%) und zweiter Art (7%) und gibt bei positivem Befund einen wahren, bei negativem
Befund einen nicht-wahren Wert ans Hauptprogramm zurück. Als Ergebnis kann der
erstaunte Perl-Enthusiast dann mit
$ ./base-rate
Test score: 9.26%
erfahren. Das Perl-Skript bestätigt also die vorher aufgestellte Überlegung zur Zuverlässigkeit des Tests an einer Personengruppe mit kleinem Anteil an wahren positiven Befunden. Eine zweite Meinung einzuholen hilft auch hier weiter.
Listings zu diesem Artikel: ftp://www.linux-magazin.de/pub/listings/magazin/2015/07/Perl
Statistics Done Wrong: The Woefully Complete Guide, Alex Reinhart, No Starch Press, 2015, http://www.amazon.com/gp/product/B00UMA61RE
Prävalenzfehler ("Base Rate Fallacy"), http://de.wikipedia.org/wiki/Pr%C3%A4valenzfehler
 |
Michael Schilliarbeitet als Software-Engineer in der San Francisco Bay Area in Kalifornien. In seiner seit 1997 laufenden Kolumne forscht er jeden Monat nach praktischen Anwendungen der Skriptsprache Perl. Unter mschilli@perlmeister.com beantwortet er gerne Ihre Fragen. |