
Auch ältere Haushaltsgeräte wie Personenwaagen oder Laserdrucker erfassen wertvolle Daten. Manuell extrahiert und grafisch ansprechend über die Zeit aufbereitet bieten sie interessante Einblicke in Nutzergewohnheiten.
Big Data erfasst ja heute unsere Bewegungen mittels Mobiltelefon, sogenannte "Wearables" messen Körperparameter wie Puls und Blutdruck, und Sensoren rund ums Eigenheim melden wer kommt und geht. Wer gerne mit den gewonnenen Daten spielt, wird diese Möglichkeiten bei dienstälteren Geräten wie etwa einer Personenwaage vermissen, die zwar schon Jahrzehnte klaglos ihren Dienst tut, aber eben keinen Web-Server mit API bietet. Mit einem einfachen Low-Tech-Ansatz und halbautomatischer Methode holt der findige Datenfreund aber auch aus diesen Oldtimern genug Informationen, um ansprechende Grafiken zu zeichnen, historische Nutzerdaten zu erfassen und daraus zukünftige Trends abzuleiten.
| |
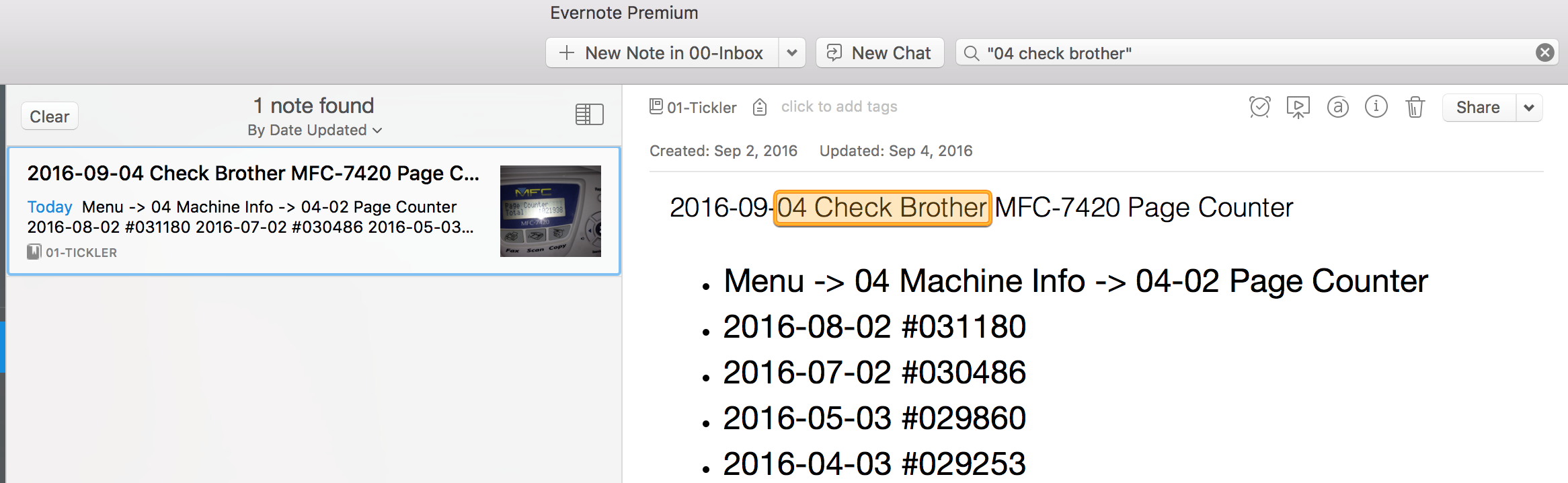
| Abbildung 1: Laut Display hat der Drucker im Laufe seines Lebens 31.651 Papierseiten bedruckt. |
Mein Brother Multifunktionsdrucker MFC-7450 bietet so zum Beispiel zwar keine digitale Schnittstelle zu seiner Reportfunktion, mich interessiert aber trotzdem, wieviele Seiten Papier so pro Monat hindurchrattern. Daraus kann ich nämlich ableiten, in welchen Zeiträumen ich neue Laser-Kartuschen nachbestellen oder ob ich in meinem Haushalt eventuell lautstark verschwenderischen Umgang mit wertvollen Resourcen anprangern muss.
 |
| Abbildung 2: Aus dem Evernote-Tickler kommt die Aufforderung, einmal im Monat den Papierstand im Drucker abzulesen und abzuspeichern. |
Die Anzahl der bedruckten Papierseiten kann ich so zwar nicht automatisch auslesen, aber wenn ich mich einmal im Monat durch das Menü auf dem Display hangele, um den lebenslangen Papierzähler des Druckers abzulesen und den aktuellen Stand aufzuschreiben, lassen sich daraus nach einem Jahr atemraubende Verbrauchskurven malen. Die Krux ist freilich, regelmäßig daran zu denken, den Zähler abzulesen, aber dazu gibt es zum Glück automatische Erinnerer.
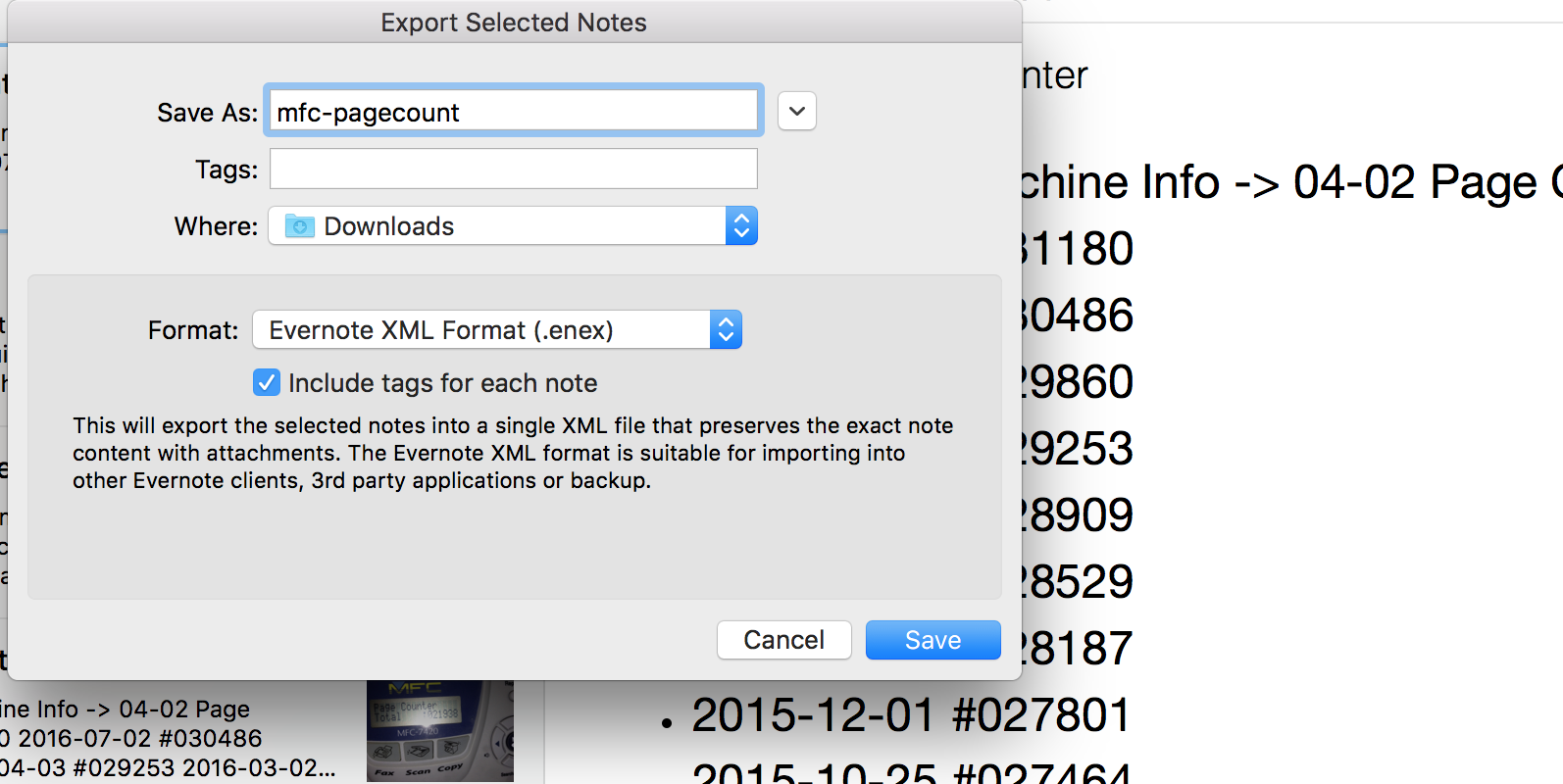 |
| Abbildung 3: Die "Export"-Funktion speichert die Evernote-Notiz als .enex-Datei im XML-Format ab. |
Hierzu nutze ich den in [2] vorgestellten Tickler-Mechanismus und den digitalen Turbonotizblock Evernote, der mir einmal im Monat den Eintrag mit den bislang notierten Zählerständen schickt, zu dem ich sofort den neuesten Stand anfügen und das Ganze wieder schlafen schicken kann. Ein entsprechender wandernder Kalendereintrag und eine Dropbox-Datei oder ein Google Spreadsheet tun es aber natürlich auch, Hauptsache, der Operateur erfasst die Daten in regelmäßigen Abständen und speichert sie permanent in der Cloud.
 |
| Abbildung 4: Aus der exportierten Evernote-Datei generiert en-extract Daten im CSV-Format. |
01 #!/usr/bin/perl -w
02 use strict;
03 use HTML::TreeBuilder::XPath;
04 use Encode qw( _utf8_on );
05
06 my $data = join "", <>;
07 _utf8_on( $data );
08 my $tree= HTML::TreeBuilder::XPath->new;
09 $tree->parse( $data );
10
11 my( @content ) = $tree->findvalues("//li");
12
13 for my $line ( @content ) {
14 $line =~ s/[#\x{c2}\x{a0}\s]+/ /g;
15 next if $line !~ /^\d/;
16 my( $date, $val ) = split " ", $line;
17 next if !defined $val;
18 print "$date,$val\n";
19 }
Evernotes "Export"-Funktion extrahiert Notizen (Abbildung 3) im
.enex-Format (einem XML-Dialekt) und das Perl-Skript in Listing 1 fieselt die
Einträge heraus, die im Format Datum/Zählerstand in
<LI>-Elementen stehen. Der
Aufruf en-extract note.enex
erzeugt Daten im CSV-Format, die Skriptsprachen später leicht maschinell
weiterverarbeiten können. Hierzu sucht das CPAN-Modul HTML::TreeBuilder::XPath
mit dem XPath-Ausdruck "//li" nach "<LI>"-Elementen in den
XML-Daten, um die in Listeneinträgen abgelegten Datumsangaben und
Papierzählerstände auszufiltern. Dieser Ansatz spart viel Zeit beim
Programmieren, denn der XPath-Parser sucht einfach nach Listenelementen in
beliebiger Verschachtelungstiefe, das Skript braucht sich also nicht daram zu
kümmern, welche XML-Elemente zum Ziel hinführen, da nur der tief verschachtelte
Inhalt interessiert. Evernote fügt leider auch noch gerne irgendwelche
närrischen Sonderzeichen in die Notizen ein, die Zeile 14 aber wieder
verwirft. Und auch etwaige Kommentare fliegen so raus, da Zeile 15
darauf besteht, dass jede Datenzeile mit einer Ziffer beginnt.
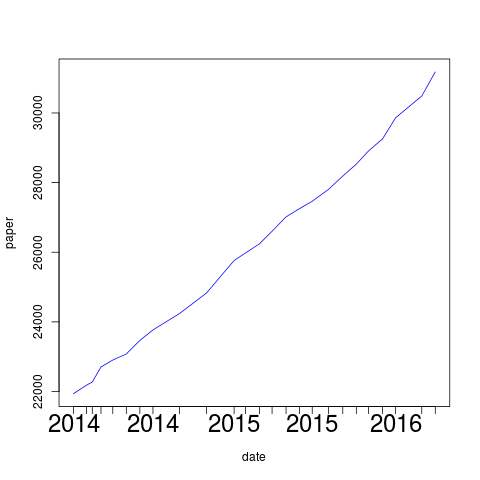 |
| Abbildung 5: Papierverbrauch im Laserdrucker über die Jahre |
Die split-Funktion in Zeile 16 spaltet Datumsangabe und Zählerstand
in zwei Elemente und Zeile 18 druckt beide
kommasepariert aus. Zum Einlesen der exportierten Evernote-Datei von der
Standardeingabe dient der Operator <>, und die nachfolgend
aufgerufene Funktion _utf8_on aus dem CPAN-Modul Encode macht einen
UTF8-String daraus. Im vorliegenden Fall liegen dort zwar keine UTF8-
sondern schlichte ASCII-Daten, aber der XPath-Parser nörgelt herum,
falls ihm ein ASCII-String übergeben wird, also gibt das klügere Skript nach.
Die so aufpolierten Daten stellen eine Zeitserie dar (Time Series, Abbildung 4), denn sie tragen Funktionswerte über die Zeit auf und zu deren grafischer Darstellung bieten allerlei Produkte mehr oder weniger ausgereifte Schnittstellen, sogar Excel-Spreadsheets halten entsprechende Funktionen für Büromäuse parat. Einige CPAN-Module widmen sich dem Thema, wie zum Beispiel Chart::Clicker ([3]) oder auch die Google-Chart-API ([4]), aber wie frühere Ausgaben des Perl-Snapshots bewiesen haben, geht es in der Sprache R wohl am schnellsten mit nur wenigen Zeilen Code ([5]).
Listing 2 zeigt das kurze R-Skript, das die CSV-Daten von der
Standardeingabe einliest und sie in einem
sogenannten Dataframe namens data ablegt. Zeile 4 dreht die Reihenfolge der
Daten, die ja chronologisch absteigend vorliegen (der menschliche Erfasser ist
faul und schreibt den neuesten Zählerstand immer an den Kopf der Datei), in
eine chronologische Reihenfolge um und weist das Ergebnis wieder data zu.
01 #!/usr/bin/env Rscript
02 args<-commandArgs(TRUE)
03 data <- read.csv(file="stdin",
04 col.names=c("date","value"))
05
06 data$date <- as.Date(data$date, "%Y-%m-%d")
07 data <- data[order(data$date,
08 decreasing=FALSE),]
09
10 png(file="timeseries.png")
11 plot(value ~ date,data,col="blue",
12 xaxt="n",type="l",ylab=args[1])
13 axis(1, data$date,
14 format(data$date, "%Y"), cex.axis=2)
Zeile 6 liest die Datumsangaben in der ersten Spalte ein und konvertiert sie in
das R eigene Datumsformat. Die png()-Funktion legt dann als Ausgabeformat
des Graphen das PNG-Format fest und die plot()-Funktion in Zeile 9 legt mit
count~date fest, dass der Graph die Variable count über der Zeitachse mit
dem Datum darstellt. Typ "l" zeichnet Linien zwischen den
Datenpunkten und der Parameter col legt dafür die Farbe Blau fest.
Normalerweise erzeugt R die Achsenbeschriftung automatisch, aber
nachdem der Graph in Abbildung 5 eine spezielle Zeitachse wünscht, die nur
die Jahresangaben des jeweiligen Datums enthält, stellt der Parameter
xaxt="n" die Automatik ab. Um die Beschriftung kümmert sich die
Funktion axis() in Zeile 13, die mit 1 die untere Achse anspricht und
das Datum $date mit %Y auf das
Jahr formatiert, sowie mit cex.axis die Fontgröße verdoppelt.
Das Skript nimmt als Kommandozeilenparameter die Beschriftung der
Y-Achse entgegen, der Aufruf timeseries.r paper am Ende der
Konvertierungs-Pipeline erzeugte also in
der Datei timeseries.png den Graphen in Abbildung 5.
Er zeigt einen linearen Anstiegs des Papierverbrauchs
über die Zeit, also ist der monatliche Verbrauch etwa konstant. Noch kein Grund
für mahnende Ansprachen, zum Glück!
 |
| Abbildung 6: Die Waage im Badezimmer zeigt 83,9kg an. |
Ganz wie dem Laserdrucker fehlt auch der Badezimmerwaage eine
digitale Reportschnittstelle. Auch hier hilft nur, das persönliche Gewicht
einmal pro Woche abzulesen, die Daten in Evernote abzulegen und
sie regelmäßig per Cronjob zu extrahieren und grafisch aufzubereiten.
Das R-Skript in Listing 2 tut auch hier Dienst, da es sich wieder
um Zeitreihen mit Zahlenwerten handelt. Mit timeseries.r weight
am Ende der Pipeline mit konvertierten Gewichtsangaben aus Evernote
aufgerufen, erzeugt sie das Diagramm in Abbildung 7.
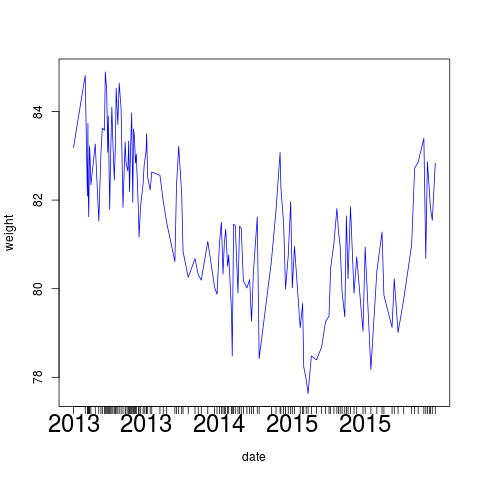 |
| Abbildung 7: Gewicht des Autors über die Zeit aufgetragen. |
Über die Jahre haben sich bei einmal wöchentlichem Wiegen etwa 140
Datenpunkte angesammelt, und das Körpergewicht schwankt beträchtlich,
sodass es anzuraten wäre, die Funktion etwas zu glätten, um besser
etwaige Tendenzen ablesen zu können. Nichts leichter als das, denn
R bietet mit loess() sogenanntes "Local Polynomial Regression Fitting"
an. Dabei legt es eine Polynomkurve an, die den Daten einigermaßen
nahekommt, sich aber nur ganz langsam schlängelt. Listng 3 zeigt die drei
Zeilen R-Code, die in Listing 2 vor dem Aufruf der plot-Funktion
eingepflanzt und die value-Spalte des Dataframes durch geglättete
Werte ersetzen.
1 data$id <- seq.int(nrow( data ))
2 lo <- loess( data$value ~ data$id )
3 data$value <- predict( lo )
Da die Regressionsfunktion nicht mit Datumsangaben umgehen kann, erzeugt die
erste Zeile in Listing 3
eine neue Spalte id im Dataframe, die die einzelnen Datenwerte
in value von 1 an durchnumeriert. Die zweite Zeile ruft dann die
eingebaute Funktion loess() auf, die mit data$value ~ data$id
eine Regressionskurve der Datenwerte über die Sequenznummern aufbaut.
Die dritte Zeile schließlich ersetzt auf einen Schlag alle Werte in
value durch diejenigen, die aus der Funktion predict() purzeln,
also die Werte des angelegten Regressionspolynoms.
Wie erwartet zeigt Abbildung 8 eine deutlich besser zu analysierende Kurve, und der Leibesfülle des Autors ist offensichtlich bald wieder Einhalt zu gebieten, wenn die sichtbare Tendenz sich fortsetzt.
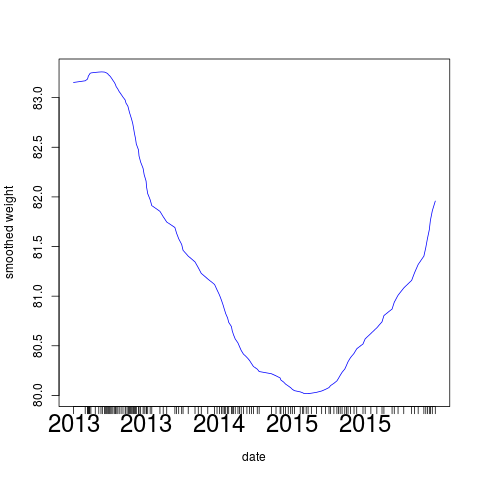 |
| Abbildung 8: Geglättete Gewichtskurve mit der loess()-Funktion |
Um die Graphen automatisch per Cronjob zu erzeugen, kann natürlich
niemand die "Export"-Funktion der Evernote-Applikation bedienen und
es muss die Evernote-API ran. Diese OAuth-basierte Webschnittstelle
bietet für Entwickler, die nur in ihren eigenen Evernote-Daten
herumfuhrwerken wollen eine vereinfachte Authentifizierung in
Form eines Developer-Tokens ([6]) an. Mit dem CPAN-Modul
Net::Evernote::Simple und dem in der Datei ~/.evernote.yml
abgelegten Token ist es dann recht einfach, lesend und schreibend
auf die Evernote-Daten zuzugreifen. Listing 4 zeigt den Zugriff
auf eine Notiz, mit einem ab Zeile 19 definierten Suchfilter, die
den Evernote-Server dazu veranlasst, aus unter Umständen vielen
tausend Einträgen den richtigen herauszufieseln.
Da die Notiz mit dem Gewichtseinträgen als einzige den Titel "Scale Weight" hat, sucht der Aufruf
$ en-fetch '"Scale Weight"'
genau diese eine Notiz und keine andere heraus, denn wegen der doppelten Anführungszeichen (noch einmal durch einfache maskiert, damit die Shell sie nicht wegputzt) wünscht die Anfrage nur exakte Treffer.
01 #!/usr/local/bin/perl
02 use strict;
03 use warnings;
04 use Net::Evernote::Simple 0.07;
05
06 my( $pattern ) = @ARGV;
07 die "usage: $0 pattern"
08 if !defined $pattern;
09
10 my $en = Net::Evernote::Simple->new();
11
12 if( ! $en->version_check() ) {
13 die "Evernote API version out of date!";
14 }
15
16 my $note_store = $en->note_store() or
17 die "getting notestore failed: $@";
18
19 my $filter = $en->sdk(
20 "EDAMNoteStore::NoteFilter" )->new(
21 { words => $pattern } );
22
23 my $offset = 0;
24 my $max_notes = 1;
25
26 my $result = $note_store->findNotes(
27 $en->{ dev_token },
28 $filter,
29 $offset,
30 $max_notes
31 );
32
33 for my $hit ( @{ $result->{ notes } } ) {
34 my $note = $note_store->getNote(
35 $en->{ dev_token }, $hit->{ guid }, 1 );
36 print $note->{ content };
37 }
Das CPAN-Modul für die Evernote-API
fußt auf mittels Thrift generiertem Perl-Code, der
aus der offiziellen Evernote-API stammt, und Zeile 12 prüft zunächst,
ob der Server die laufende Client-Version überhaupt noch unterstützt
oder ein Upgrade fordert. Die Methode note_store() in Zeile 16
erzeugt dann ein Objekt vom Typ EDAMNoteStore, das später auf den
Evernote-Speicher eines Users zugreift. Zeile 19 definiert einen neuen
Filter, den Anfragen an den Server mitliefern, damit dieser wirklich nur
passende Notizen liefern. Eine der Filtermöglichkeiten der API ist
die nach Stichworten mit dem Parameter words, weitere wären Tags oder
"Notebooks" genannte Verzeichnisse, in denen die Notizen liegen.
Da solche Anfragen unter Umständen viele Treffer liefern, verlangt die
Methode findNotes() in Zeile 26 noch die Angabe der Maximalzahl der
Treffer sowie mit $offset den Start der Paginierung, falls der Client
die Ergebnisse in Schüben einholt und den nächsten Schub verlangt. Da
im vorliegenden Fall der Such-Query so formuliert sein sollte, dass er
genau auf eine Notiz passt, setzt Listing 4 $offset auf 0 und
die Maximalzahl auf 1. Als zweiten Parameter verlangt findNotes() den
Developer-Token, den das CPAN-Modul anfangs aus ~/.evernote.yml gelesen
hat und nun unter dem Hash-Schlüssel dev_token parat hält.
Die for-Schleife ab Zeile 33 iteriert über die Suchtreffer, extrahiert
zu jeder gefundenen Notiz deren eindeutige guid und holt dann damit
und mittels getNote() den Inhalt der Notiz vom Server. Im Feld content
steht dann der XML-Salat, den en-extract (Listing 1) in eine
Zeitserie im CSV-Format transformiert, und der letzte Teil der Pipeline
zeichnet wie vorher den Graphen.
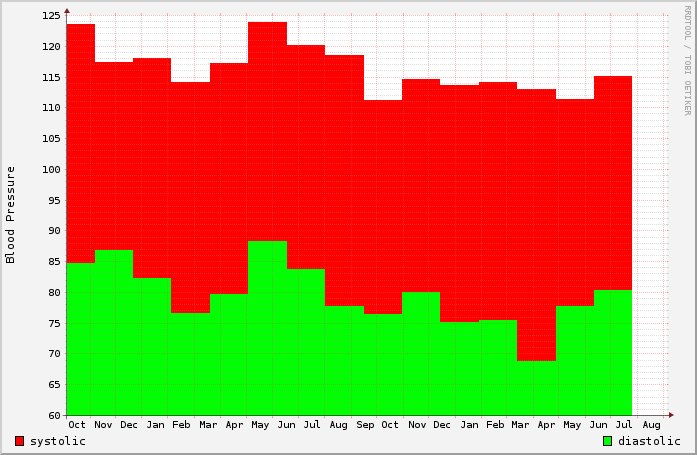 |
| Abbildung 9: Blutdruck-Diagramm mit systolischen und diastolischen Werten über mehrere Jahre. |
Mit einem preiswerten Gerät der Firma Omron messe ich weiterhin alle paar Wochen mal meinen Blutdruck und schreibe die beiden Werte, den höheren systolischen und den niedrigeren diastolischen, in eine Evernote-Datei. Über die Jahre gesammelte Daten ergeben sich dann so nette Diagramme wie in Abbildung 10.
 |
| Abbildung 10: Einmal im Monat wandern die von diesem Blutdruckmessgerät gelieferten Werte in eine Datenbank. |
01 #!/usr/bin/perl -w
02 use strict;
03 use DateTime::Format::Strptime;
04
05 my $strp = DateTime::Format::Strptime->new(
06 pattern => "%Y-%m-%d",
07 );
08
09 while( <> ) {
10 chomp;
11 my( $date, $value ) = split /,/, $_;
12 my $dt = $strp->parse_datetime( $date );
13 printf "%d,%s\n", $dt->epoch, $value;
14 }
Neben den eingangs erwähnten Alternativen zum Zeichnen der Graphen
von Zeitserien kennen leicht ergraute Leser vielleicht noch das
ehrwürdige RRDTool. Es verlangt einige Klimmzüge beim Einfüttern der
Daten und das Format der Beschreibungssprache ist etwas maschinennah
und unleserlich. Das CPAN-Modul RRDTool::OO gestaltet den Vorgang
etwas augenfreundlicher, aber die Tatsache bleibt, dass RRDTool seine
Daten in streng chronologischer Reihenfolge erwartet und schon beim Anlegen
einer Datenbank den Zeitstempel des ersten Wertes wissen muss. Weiter
nimmt es die Zeitangaben in Unix-Sekunden seit 1970 an, also konvertiert
Listing 5 hereinkommende Daten mit Zeitstempeln im Format JJJJ-MM-TT
mittels des CPAN-Moduls DateTime in Epoch-Sekunden und ein nachfolgendes
sort in der Unix-Pipeline bringt sie in eine chronologische Reihenfolge
für die RRD-Auswertung in ts2rrd aus Listing 6:
... | ts2epoch | sort | ts2rrd
Der Graph-Generator sammelt zunächst Datenpunkte wie
"2016-01-01 120:80" in einem Array von Arrays namens @points,
um später das Datum des ersten Datenpunkts für RRDTools create-Methode
parat zu haben, so wie später beim Zeichnen des Graphen die Zeitstempel
des ersten und des letzten Datenpunktes. Es definiert zwei von
RRDTools "data_source"-Strukturen, eine für den diastolischen und eine
für den systolischen Blutdruck über die Zeit.
Jeder Aufruf der update-Methode in Zeile 26 füttert dann sowohl den
Zeitstempel des Datenpunktes als auch die beiden Werte für den Blutdruck
in die Round-Robin-Datenbank. Da RRDTool Alarm schlägt, falls mal ein
Datenpunkt ausbleibt, definiert Zeile 17 den Parameter step und
setzt ihn auf 45 Tage, und da die Messwerte mindestens einmal im Monat
eintrudeln, entsteht so kein Loch.
01 #!/usr/bin/perl -w
02 use strict;
03 use RRDTool::OO;
04
05 my @points = ();
06
07 while( <> ) {
08 chomp;
09 my($time, $value) = split /,/, $_;
10 push @points, [$time, split /:/, $value];
11 }
12
13 my $rrd = RRDTool::OO->new(
14 file => "ts.rrd" );
15
16 $rrd->create(
17 step => 3600*24*45,
18 start => $points[0]->[0] - 1,
19 data_source => { name => "high",
20 type => "GAUGE" },
21 data_source => { name => "low",
22 type => "GAUGE" },
23 archive => { rows => 10_000 });
24
25 for(@points) {
26 $rrd->update(
27 time => $_->[0],
28 values => [ @{ $_ }[1,2] ] );
29 }
30
31 $rrd->graph(
32 width => 600,
33 height => 400,
34 image => "blood-pressure.png",
35 vertical_label => "Blood Pressure",
36 start => $points[0]->[0],
37 end => $points[-1]->[0],
38 draw => {
39 legend => "systolic",
40 dsname => "high",
41 type => "area",
42 color => "FF0000",
43 },
44 draw => {
45 legend => "diastolic",
46 dsname => "low",
47 type => "area",
48 color => "00FF00",
49 }
50 );
Beim Zeichnen des Diagramms ab Zeile 31 definieren die beiden draw-Parameter
zwei verschiedene Graphen für die beiden Blutdruckwerte über die Zeit, wobei
der systolische Wert ein rotest Rechteck ("area", "FF0000")
zugewiesen bekommt, und der diastolische Werte eines in Grün
("00FF00"). Die Ausgabe erfolgt in eine Bilddatei namens blood-pressure.png,
wie sie in Abbildung 9 zu sehen ist. Auf diese Weise zeigen sich interessante
Entwicklungen, die beim regelmäßigen Messen ohne statistische Analyse
vielleicht unter den Tisch fallen würden. Pumperlgesund dank Zeitreihen!
Listings zu diesem Artikel: http://www.linux-magazin.de/pub/listings/magazin/2016/11/perl-snapshot
"Unvergesslich", Michael Schilli, Linux-Magazin 2012/04, http://www.linux-magazin.de/Ausgaben/2012/04/Perl-Snapshot
"Bewegte Reife" Michael Schilli, Linux-Magazin 2013/10, http://www.linux-magazin.de/Ausgaben/2013/10/Perl-Snapshot
"Datenmaler" Michael Schilli, Linux-Magazin 2009/07, http://www.linux-magazin.de/Ausgaben/2009/07/Datenmaler
"Kurzweilige Repository-Statistiken mit Perl und R", Michael Schilli, Linux-Magazin 2011/02, http://www.linux-magazin.de/Ausgaben/2011/02/Datumsarithmetik
Evernote Developer Tokens, https://www.evernote.com/api/DeveloperToken.action
 |
Michael Schilliarbeitet als Software-Engineer in der San Francisco Bay Area in Kalifornien. In seiner seit 1997 laufenden Kolumne forscht er jeden Monat nach praktischen Anwendungen der Skriptsprache Perl. Unter mschilli@perlmeister.com beantwortet er gerne Ihre Fragen. |