Automatisches Absaugen von Webseitendaten ist so alt wie das Web selbst. Solange es Webseiten zum Anschauen für Massen von Browserkunden im Netz gibt, sitzen auf der Konsumentenseite auch einige, die die Daten in einem anderen Format haben wollen und deshalb Scraper-Skripts schreiben. Dies verstößt zwar oft gegen die von Webseitenbetreibern geforderten Terms of Service (ToS), aber solange die Sauger die Daten nicht kommerziell verwerten oder die Webseite zu heftig mit Anfragen bombardieren, regt sich keiner darüber auf.
Perl-Füchse schätzen hierzu WWW::Mechanize, Python-Afficinados vielleicht das selenium-Paket ([2]), und in Go bieten auch gleich mehrere Pakete Scraper-Dienste an. Eines der neueren ist Colly (wohl von "collect", Einsammeln) und wie in Go üblich lässt es sich einfach direkt vom Github-Repo mittels
go get github.com/gocolly/collycompilieren und installieren. Anschließend kann zum Beispiel ein Programm wie Listing 1 auf die Webseite des Nachrichtensenders CNN zugreifen, sich durch die im HTML der Seite versteckten Links wühlen und diese zu Testzwecken ausgeben.
Wie in Go üblich, erzeugt go build linkfind.go ein Binary linkfind, das zwar mit 14MB reichlich gewampert daherkommt, aber eben alle abhängigen Bibliotheken schon enthält, und auf ähnlichen Architekturen ohne Fiesematenten läuft. Dass Go die heutzutage gängige "Dependency Hell" von der Laufzeit zum Compile-Zeitpunkt verlagert und dem End-User die Arbeit abnimmt, ist wohl eine der großartigsten Ideen überhaupt.
01 package main
02
03 import (
04 "fmt"
05 "github.com/gocolly/colly"
06 )
07
08 func main() {
09 c := colly.NewCollector()
10
11 c.OnHTML("a[href]",
12 func(e *colly.HTMLElement) {
13 fmt.Println(e.Attr("href"))
14 })
15
16 c.Visit("https://cnn.com")
17 }
Listing 1 initialisiert in Zeile 9 mit NewCollector() hierzu eine neue Colly-Struktur, deren Funktion Visit() später die URL der Webseite von CNN anfährt und den Callback OnHTML() anspringt, sobald das HTML der Seite eingetrudelt ist. Der Selector "a[href]" ruft den nachfolgenden func-Code nur für Links im Format <A HREF=...> auf, übergibt ihr einen Pointer auf eine Struktur vom Typ colly.HTMLElement, und damit liegt dort in e.Attr("href") die Link-URL als String vor.
Das Ganze lässt sich noch etwas verfeinern, wie schwierig wäre es, festzustellen, welche HTML-Anker zu externen Webseiten verzweigen und welche die Seite intern verlinken? Listing 2 baut auf dem gleichen Grundgerüst auf, definiert aber noch eine Zählerstruktur Stats, und verdrahtet den zu untersuchenden URL nicht mehr fest im Code, sondern nimmt ihn als Parameter auf der Kommandozeile entgegen.
01 package main
02
03 import (
04 "fmt"
05 "github.com/gocolly/colly"
06 "net/url"
07 "os"
08 )
09
10 type Stats struct {
11 external int
12 internal int
13 }
14
15 func main() {
16 c := colly.NewCollector()
17 baseURL := os.Args[1]
18
19 stats := Stats{}
20
21 c.OnHTML("a[href]",
22 func(e *colly.HTMLElement) {
23 link := e.Attr("href")
24 if linkIsExternal(link, baseURL) {
25 stats.external++
26 } else {
27 stats.internal++
28 }
29 })
30
31 c.Visit(baseURL)
32
33 fmt.Printf("%s has %d internal "+
34 "and %d external links.\n", baseURL,
35 stats.internal, stats.external)
36 }
37
38 func linkIsExternal(link string,
39 base string) bool {
40 u, err := url.Parse(link)
41 if err != nil {
42 panic(err)
43 }
44 ubase, _ := url.Parse(base)
45
46 if u.Scheme == "" ||
47 ubase.Host == u.Host {
48 return false
49 }
50 return true
51 }
Um externe von internen Links zu unterscheiden, zerlegt die Funktion linkIsExternal() ab Zeile 38 sowohl den Link-URL als auch den ursprünglichen Basis-URL mit Parse() aus dem Paket net/url in seine Einzelteile, und sieht dann nach, ob er mit http(s):// beginnt (mittels Schema()) oder der Host in beiden URLs identisch ist -- in beiden Fällen verweist der Link wieder auf die ursprüngliche Seite, ist also intern.
Zeile 19 initialisiert eine Instanz der Struktur Stats, und wie in Go üblich, erhalten alle Mitglieder ihre Default-Werte zugewiesen, im Fall der beiden Integer also jeweils den Wert 0 . So brauchen die Zeilen 25 und 27 für jeden untersuchten Link nur jeweils den Integerwert um Eins hochzuzählen, und am Ende des Programms kann Zeile 33 die Anzahl der internen vs. externen Links ausgeben. Für die Startseite des Linux-Magazins ergibt sich
$ ./linkstats https://www.linux-magazin.de
https://www.linux-magazin.de has
588 internal and 16 external links.also eine ganz schön komplexe Webseite! Doch Linksammeln erschöpft die Funktion von Colly noch lange nicht. Die Dokumentation auf [3] ist zwar noch etwas spärlich, aber anhand der dort veröffentlichten Beispiele kann der Interessierte weitere Anwendungsbereiche ableiten.
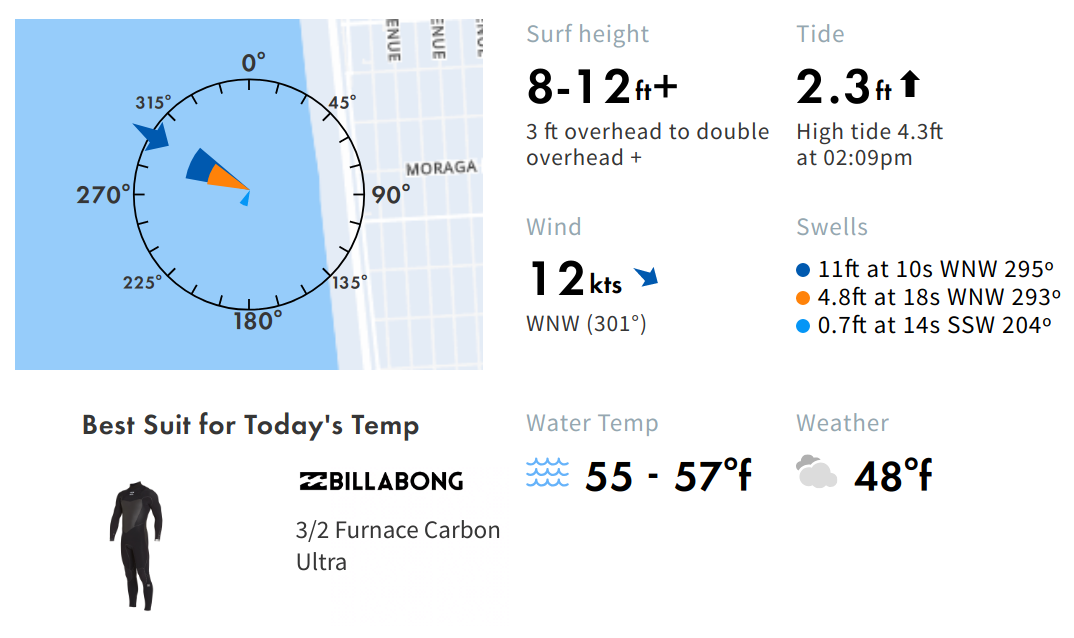
Zum Beispiel zeigt die Webseite surfline.com die Höhe der Wellen an ausgewählten Stränden der Welt an, und da ich ja fürs Leben gern Surfen gehe, bietet sich ein Kommandozeilentool an, das schnell auf die Seite meines Hausstrands "Ocean Beach" in San Francisco schaut, und nachsieht, ob irgendwelche Monsterwellen dagegen sprechen, rauszupaddeln, denn bei mehr als zwei Metern flattert mir als Hobbysurfer gehörig der Wetsuit. Abbildung 1 zeigt die Informationen auf der Webseite, Abbildung 2 illustriert, wo sich die Daten im HTML der Seite laut Chromes "Developer Tools" verstecken. Aufgabe des Scrapers ist es nun, sich durch die Tags zu hangeln und die Zahlenwerte herauszufieseln.
| |
| Abbildung 1: Aktuelle Surfbedingungen auf surfline.com |
 |
| Abbildung 2: Die Höhe der Wellen steht mitten im HTML in einem Tag der Klasse "quiver-surf-height". |
Im vorliegenden Fall findet sich die Angabe der Wellenhöhe in einem span-Tag der Klasse .quiver-surf-height, allerdings ist dieses Tag mehrfach im Dokument vertreten, weil die Seite auch die Konditionen an anderen benachbarten Surfspots anzeigt. Der Trick besteht nun darin, einen Pfad von der Dokumentwurzel zu den Daten zu finden, der eindeutig ist, und wie Abbildung 2 zeigt, führt dieser Pfad über ein Element der Klasse .sl-spot-forecast-summary. Die Programmierung geht flugs von der Hand, kaum erhält die OnHTML()-Funktion in Zeile 12 von Listing 3 beide Klassennamen als Leerzeichen-separierten String als erstes Argument, bohrt sich der Query-Prozessor genau auf diesem Pfad ins Dokument hinein und findet nur eine, nämlich die richtige Wellenhöhe des aktuell ausgewählten Spots.
Aber hoppla, im gefundenen span-Element befinden sich nun drei Zeilen, die erste gibt mit "8-12" die gesuchte Wellenhöhe an, aber die zweite stellt im Browser mit <sup>FT>/sup> noch ein Fuß-(das amerikanische Längenmaß)-Zeichen daneben und die dritte Zeile gibt mit "+" noch an, dass es auch ein bisserl mehr sein kann. Wie kann der Query-Prozessor diese drei Zeilen nun trennen? In der Colly-Dokumentation fand ich dazu nichts, aber zum Glück nutzt Colly intern die Querysprache Goquery, die jQuery sehr ähnlich ist, und von einer in Colly gefundenen Struktur vom Typ HTMLElement kommt man über deren Attribut DOM schnell zur zugehörigen goquery-Struktur.
Deren Dokumentation ([4]) führt aus, dass die Funktion Contents() auf das gefundene Element den Text in seine drei Teile zerlegt, ein nachfolgender Aufruf von Slice(0,1) schneidet den ersten Teil heraus. Wie in Go üblich beziehen sich die Indexnummern für ein Slice immer auf den Anfang (einschließlich) und das letzte Element (ausschließlich). Das nachfolgende Each() schnappt sich also nur das eine Ergebnis, ruft mit der gefundenen Selektion die nachgeschaltete Callback-Funktion auf und diese extrahiert mit s.Text() den Text mit der Höhenangabe. Puh, ganz schön kompliziert!
01 package main
02
03 import (
04 "fmt"
05 "github.com/gocolly/colly"
06 "github.com/PuerkitoBio/goquery"
07 )
08
09 func main() {
10 c := colly.NewCollector()
11
12 c.OnHTML(".sl-spot-forecast-summary " +
13 ".quiver-surf-height",
14 func(e *colly.HTMLElement) {
15 e.DOM.Contents().Slice(0,1).Each(
16 func(_ int, s *goquery.Selection) {
17 fmt.Printf("%s\n", s.Text())
18 })
19 })
20
21 c.Visit("https://www.surfline.com/" +
22 "surf-report/ocean-beach-overview/" +
23 "5842041f4e65fad6a77087f8")
24 }
Der Aufruf des kompilierten Binaries mit
$ ./surfline
8-12zaubert so zutage, dass die Wellenhöhe mit 8 bis 12 Fuß (2.4-3.6m) etwas über meinen Möglichkeiten liegt und ich das Surfbrett aus Sicherheitsgründen besser zuhause lasse. Aber morgen ist ja auch noch ein Tag!
Listings zu diesem Artikel: http://www.linux-magazin.de/static/listings/magazin/2019/04/snapshot/
Michael Schilli, "Serviler Wächter": Linux-Magazin 02/17, S.xxx, <U>http://www.linux-magazin.de/ausgaben/2017/12/snapshot/<U>
"Colly, Fast and Elegant Scraping Framework for Gophers", http://go-colly.org/docs/
Goquery Dokumentation, https://godoc.org/github.com/PuerkitoBio/goquery
 |
Michael Schilliarbeitet als Software-Engineer in der San Francisco Bay Area in Kalifornien. In seiner seit 1997 laufenden Kolumne forscht er jeden Monat nach praktischen Anwendungen verschiedener Programmiersprachen. Unter mschilli@perlmeister.com beantwortet er gerne Ihre Fragen. |
Hey! The above document had some coding errors, which are explained below:
Unknown directive: =desc
Unterminated C<...> sequence