
Lange schon bevor es die ersten Computer gab, beschäftigte das Sortieren von Daten die Menschheit. Der Exildeutsche Herman Hollerith erfand schon um 1890 eine elektro-mechanische Maschine, die Lochkarten in verschiedene Ausgangsschächte sortierte, um die Auswertung der damaligen USA-Volkszählung zu beschleunigen (Abbildung 1). Und auch heute sortieren Computer laufend Daten, hier für eine Liste gezielt vorgeschlagener Youtube-Videos, dort die Top-100-Charts der Musikindustrie nach Verkaufszahlen, oder für die Performance-Analyse die langsamsten Queries aus einer MySQL-Datenbank -- maschinell sortiert wird auf Teufel komm raus.
Dabei verändern Programme die Reihenfolge beliebig geformter Datenstrukturen, als Sortierkriterium dient aber meist ein einfacher Schlüssel, oft eine Integerzahl oder ein String. Deshalb zeigt die klassische Literatur zu Sortieralgorithmen ([4], [5]) oft nur, wie sie eine Reihe von Zahlen sortieren, denn die Portierung auf komplexere Datenstrukturen ist durchwegs trivial und durch eine einfache Zuordnung vom Schlüssel zur Datenstruktur zu bewältigen.
| |
| Abbildung 1: Lochkartensortiermaschine von IBM aus dem Jahr 1949 (Quelle: Wikipedia https://en.wikipedia.org/wiki/Radix_sort By Adam Schuster - Flickr: Proto IBM, CC BY 2.0, https://commons.wikimedia.org/w/index.php?curid=13310425 |
Als einfachsten Sortieralgorithmus lernen Programmieranfänger oft den Bubble Sort mit seinen zwei for-Schleifen kennen. Mittels der ersten Schleife hangelt der Index i sich von links nach rechts durch die Elemente eines Arrays. Zu jedem untersuchten Element startet eine weitere for-Schleife, die alle folgenden Elemente abklappert, und sicherstellt, dass das untersuchte Element der ersten Schleife kleiner als alle folgenden ist. Findet das Verfahren ein kleineres Element weiter rechts, vertauscht es dieses kurzerhand mit dem Untersuchten. So stellt die erste Schleife sicher, dass jedes bearbeitete Element kleiner als alle folgenden ist -- und am Ende, wenn die erste Schleife am rechten Rand anschlägt, ist der Array aufsteigend sortiert (Abbildung 2).
01 package main
02
03 import (
04 "fmt"
05 )
06
07 func main() {
08 items := []string{"green", "red",
09 "blue", "black", "white"}
10
11 for i, _ := range items {
12 for j := i + 1; j < len(items); j++ {
13 if items[i] > items[j] {
14 items[i], items[j] =
15 items[j], items[i]
16 }
17 }
18 }
19
20 fmt.Printf("%+v\n", items)
21 }
Listing 1 zeigt in der ersten for-Schleife ab Zeile 11 den range-Operator, der zu jedem Element des Array-Slice items den bei 0 startenden Index und das Element selbst zurückliefert. Letzteres ignoriert der Schleifenkopf, indem er es der Pseudo-Variablen _ zuweist, da ihn nur der Index interessiert. Die zweite for-Schleife ab Zeile 12 startet beim Element direkt rechts davon, der Index j fängt es bei i+1 an zu laufen. Findet es auf Indexposition j ein Element, das größer ist als das von i referenzierte, vertauscht es beide kurzerhand mit dem in Go so praktischen Konstrukt a,b = b,a. Mit go build bubble.go compiliert, zeigt das Programm die sortierte Farbenliste:
$ ./bubble
[black blue green red white]Der Bubble-Sort ist leicht zu verstehen, braucht aber verhältnismäßig viele (O(n^2)) Schritte zur Sortierung. Da bieten oft schlauere Verfahren wie Mergesort oder Quicksort bessere Performance. Bei kleinen Datenmengen, zum bei Beispiel Arrays mit bis zu 5 Elementen, ist der Bubble-Sort aber gut genug. Er sortiert die Einträge im Original-Array ohne externe Speicherbedürfnisse, ist stabil (die Reihenfolge gleicher Elemente bleibt unverändert) und vor allem bei fast vollständig sortierten Eingangsdaten blitzschnell.
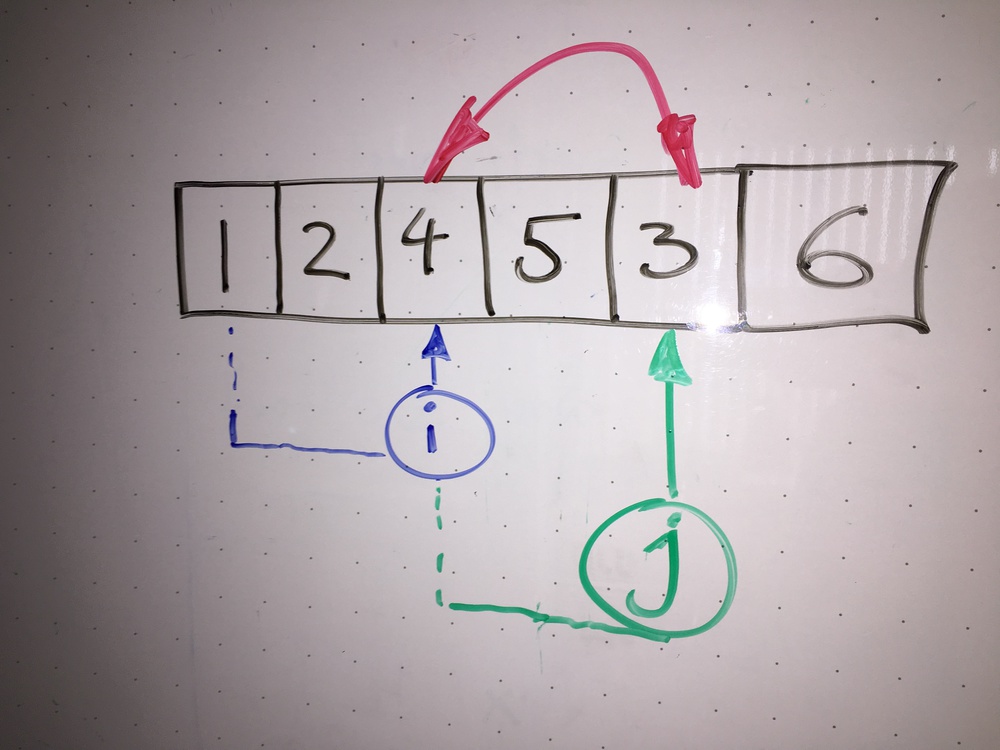 |
| Abbildung 2: Die zwei Schleifenvariablen i und j im Bubble Sort hangeln sich durch den Array und vertauschen unsortierte Elemente. |
Bei Bewerbungsgesprächen kommt manchmal die Frage nach schnellen Suchalgorithmen auf, und bevor der Applikanten reflexartig "Quicksort" hervorsprudelt, gilt es sorgfältig abzuwägen, ob nicht besondere Rahmenbedingungen des gestellten Problems trickreichere Verfahren zulassen. Besteht der zu sortierende Korpus zum Beispiel nur aus wenigen verschiedenen Schlüsseln, ist der sogenannte Countingsort eventuell noch schneller.
 |
| Abbildung 3: Drei Stufen des Countingsort: Histogramm, Indexberechnung, Endresultat. |
In Listing 2 stehen im zu sortierenden Array things nur die Werte 3, 4 und 5. Statt nun anzufangen, wild Elemente zu vertauschen, tabuliert der Algorithmus lediglich in einem Array count an den Indexpositionen 3, 4 und 5 auf, wie oft die verschiedenen Werte im Sortier-Array vorkommen. An der Indexposition 3 steht so später der Wert 7, denn in things stehen sieben Dreien, an der Indexposition 4 eine Fünf für die fünf Vierer in things, und so weiter.
Da die Suchroutine am Anfang nicht weiß, welche Schlüssel im zu sortierenden Array auftauchen, legt sie zunächst einen leeren count-Array an. Will dann die for-Schleife ab Zeile 14 einen Eintrag in count an der Indexposition thing anlegen, streckt Zeile 16 count mittels der eingebauten Funktion append() auf die geforderte Größe. Im Gegensatz zu typischen Skriptsprachen arbeitet Go nämlich nicht mit dynamisch wachsenden, sondern statisch festgelegten Arrays. Legt ein Programm einmal einen neuen Array mit drei Elementen mittels make([]int, 3) an, und greift später auf ein Element außerhalb des Bereiches 0 bis 2 zu, wirft Go einen Runtime-Fehler und bricht das Programm ab. Das gleiche gilt übrigens auch für Array-Slices: Diese definieren nur ein Fenster auf einen bestehenden Array, und der lässt sich nur erweitern, indem die eingebaute Funktion append() einen neuen erzeugt, deren zweiter und alle folgenden Parameter neue angehängte Elemente definieren. So macht Zeile 16 aus dem alten, zu kurzen Array count einen neuen, der um die Differenz aus dem gewünschten Index (in der Variablen thing) und dem letzten Index des bestehenden Arrays längeren Array und weist ihn wieder dem ursprünglichen count zu. Dazu kreiert es mit make() einen kleinen Array, der die Differenz auffüllt, und gibt seine Elemente einzeln (mit ... aufgedröselt) der Funktion append() zu futtern.
Nach der ersten for-Schleife stehen im Array count ab Zeile 21 die Zähler für die eingesammelten Schlüssel. Die zweite for-Schleife ab Zeile 24 iteriert nun über die Zähler in count und füllt den Array things erst mit sieben Dreien, dann mit fünf Vieren, und so weiter. Das Verfahren nutzt zwar einen externen Array count zum Zählen, dessen Größe fällt aber bei wenigen verschiedenen Schlüsseln nicht ins Gewicht. Die Sortierung erfolgt in-place, modifiziert also den Original-Array. Die Anzahl der benötigten Schritte ist linear (O(n)), das Verfahren ist also bei großen Datenmengen um Größenordnungen schneller als selbst die ausgefuchsteste generische Sortierfunktion -- allerdings natürlich nur wegen der ganz speziellen Form der Eingangsdaten.
01 package main
02
03 import (
04 "fmt"
05 )
06
07 func main() {
08 things := []int{5, 4, 3, 3, 3, 4, 4,
09 4, 4, 5, 5, 3, 3, 3, 3}
10 fmt.Printf("%+v\n", things)
11
12 count := []int{}
13
14 for _, thing := range things {
15 if len(count) <= thing {
16 count = append(count, make([]int,
17 thing - len(count) + 1)...)
18 }
19 count[thing]++
20 }
21 fmt.Printf("count=%+v\n", count)
22
23 idx := 0
24 for val, run := range count {
25 for x := 0; x < run; x++ {
26 things[idx] = val
27 idx++
28 }
29 }
30
31 fmt.Printf("%+v\n", things)
32 }
Wenn Kartenspieler ein neues Blatt aufnehmen, sortieren sie einzeln aufgenommene neue Karten in die bestehende Hand ein, indem sie an der einzufügenden Stelle Platz machen, also niederwertigere Karten nach links, höherwertige Karten nach rechts rücken, und die neue Karte in den enstehenden Zwischenraum einfügen (Abbildung 4). Genau so funktioniert auch der Insertion Sort, ein Verfahren, das in-place sortiert und kurz und bündig daherkommt, aber einige geistige Klimmzüge erfordert ([4], [5]).
 |
| Abbildung 4: Beim Aufnehmen eines Blattes sortiert der Kartenspieler neue Karten ein, indem er in der Hand an der entsprechenden Stelle Platz macht. |
Dazu teilt der Algorithmus den zu sortierenden Array in zwei Abschnitte, links die bereits soweit sortierten Elemente, rechts die unsortierten. Dazu bestimmt er ein aktuell zu untersuchendes Element, beginnend mit dem zweiten des Arrays. In Abbildung 5 ist dies zunächst die Vier. Links davon steht in der bereits "sortierten" Liste nur die Drei, rechts davon, beginnend mit der Eins, der bis dato unsortierte Teil. Nun prüft eine nach links hoppelnde Schleife, wo das aktuelle Element einzufügen ist. Da das aktuelle Element (Vier) größer als das einzige sortierte Element weiter links ist, gibt es nichts weiter zu tun, und der Algorithmus schreitet zum nächsten aktuellen Element fort.
 |
| Abbildung 5: Verschobene Elemente beim Insertion Sort. |
Im nächsten Schritt in Abbildung 5 ist die Eins das aktuelle Element, und die nach links hoppelnde Schleife prüft, wo es im sortierten Teil einzufügen ist. Sie sieht zunächst die Vier, stellt fest, dass das aktuelle Element links davon gehört und schiebt die Vier um eins nach rechts (Schritt (a)), an die vorige Stelle des aktuellen Elements, das sie vorher in einer Variablen gesichert hat. Weiter links sieht sie die Drei, die ebenfalls rechts des aktuellen Elements stehen sollte und schiebt sie an die vorige Position der Vier (Schritt (b)). Nun steht nichts mehr im Weg, und die gesicherte aktuelle Eins kann an die erste Position des Arrays wandern (Schritt (c), die Folge ist nun "1, 3, 4, ..." und der Algorithmus setzt sich fort mit der Zwei als aktuelles Element.
 |
| Abbildung 6: Der Insertion-Sort von Listing 3 sortiert den Array, indem es aus der Reihe fallende Werte von links nach rechts Stück für Stück an der richtigen Stelle einschiebt. |
Das Ganze implementiert Listing 3 relativ kompakt, die for-Schleife ab Zeile 11 bestimmt das aktuelle Element, beginnend mit j=1, also dem zweiten Element des bei Indexposition 0 startenden Arrays. Die Ausgabe von Listing 3 mit den verschiedenen Sortierschritten und dem jeweils aktuellen Element key zeigt Abbildung 6.
01 package main
02
03 import (
04 "fmt"
05 )
06
07 func main() {
08 things := []int{3, 4, 1, 2, 6, 5, 8, 7}
09 fmt.Printf("%+v\n", things)
10
11 for j := 1; j < len(things); j++ {
12 key := things[j]
13 fmt.Printf("key=%d\n", key)
14 i := j - 1
15 for i >= 0 && things[i] > key {
16 things[i+1] = things[i]
17 i--
18 }
19 things[i+1] = key
20 fmt.Printf("%+v\n", things)
21 }
22 }
Die nach links hoppelnde Prüfschleife zum Platzmachen im sortierten Teil beginnt in Zeile 15 mit i=j-1 und setzt sich fort, bis sie auf ein sortiertes Element trifft, das kleiner oder gleich dem aktuellen ist, oder mit i<0 am linken Rand aus dem Array purzeln würde. In jedem Schleifendurchgang kopiert Zeile 16 ein Element im sortierten Bereich um eins nach rechts, und i verringert sich um Eins. Am Ende der Schleife kopiert Zeile 19 das in key zwischengespeicherte aktuelle Element an die freigewordene Stelle, und die äußere for-Schleife geht in die nächste Runde. Allerdings wächst die Anzahl der beim Insertion Sort benötigten Schritte quadratisch mit der Anzahl der Elemente, er ist also nicht schneller als der Bubble Sort. Für beliebige Eingangsdaten gibt es in der Tat schlauere Verfahren, die die Anzahl der Schritte von O(n^2) auf O(n*lg(n)) reduzieren. Wie soll das nun gehen?
Bessere Verfahren nutzen oft das Verfahren "Divide and Conquer" ("teile und herrsche), lösen also nicht das ganze Problem in einem Rutsch, sondern teilen es in zwei einfacher zu lösende Teilprobleme, die sie dann rekursiv in Angriff nehmen. Am Mergesort gefällt seine beinahe triviale Implementierung aus reiner Rekursion. Der Trick besteht darin, den Array zu halbieren, die zwei Hälften individuell zu sortieren und dann die zwei sortierten Stapel so miteinander so zu einem neuen zu mischen, dass wieder ein sortierter Stapel herauskommt. Das individuelle Sortieren ist eigentlich gar keines, denn die Sortierfunktion halbiert wiederum das Array und ruft sich selbst auf die beiden Hälften immer wieder selbst auf, bis ein Array mit nur einem Element daherkommt, den die Funktion dann als "sortiert" deklariert und unverändert zurückgibt.
Das eigentliche Schmalz des Verfahrens steckt in der Funktion merge(), die zwei sortierte Arrays zusammenfügt. Dazu schreitet sie durch die Elemente der beiden sortierten Stapel, vergleicht die beiden aktuellen Elemente, entfernt das jeweils niedrigere und legt es auf den Ergebnisstapel. Abbildung 7 illustriert das Verfahren anhand eines Kartenspiels, das die beiden oberen Stapel einem ebenfalls sortierten unten liegenden kombiniert.
01 package main
02
03 import (
04 "fmt"
05 )
06
07 func main() {
08 things := []int{17, 34, 42, 1, 7, 9, 8}
09
10 fmt.Printf("%+v\n", things)
11 mergesort(things, 0, len(things)-1)
12 fmt.Printf("%+v\n", things)
13 }
14
15 func mergesort(a []int, p, r int) {
16 if p < r {
17 q := (p + r) / 2
18 mergesort(a, p, q)
19 mergesort(a, q+1, r)
20 merge(a, p, q, r)
21 }
22 }
23
24 func merge(a []int, p, q, r int) {
25 left := make([]int, q-p+1)
26 right := make([]int, r-q)
27
28 copy(left, a[p:])
29 copy(right, a[q+1:])
30
31 fmt.Printf("left=%d\n", left)
32 fmt.Printf("right=%d\n", right)
33
34 lidx := 0
35 ridx := 0
36 oidx := p
37
38 for lidx < len(left) &&
39 ridx < len(right) {
40 if left[lidx] < right[ridx] {
41 a[oidx] = left[lidx]
42 lidx++
43 } else {
44 a[oidx] = right[ridx]
45 ridx++
46 }
47 oidx++
48 }
49 for lidx < len(left) {
50 a[oidx] = left[lidx]
51 lidx++
52 oidx++
53 }
54 for ridx < len(right) {
55 a[oidx] = right[ridx]
56 ridx++
57 oidx++
58 }
59 }
In Listing 4 nimmt merge() ab Zeile 24 einen Integer-Array a entgegen, sowie drei Indexpositionen p, q und r. Die zwei Teil-Arrays, die merge() zusammenfügen soll, liegen an den Positionen p bis q, sowie q+1 bis r. Das Ergebnis legt sie in-place im Original-Array a ab. Das setzt aber voraus, dass merge() zunächst eine Kopie des linken und des rechten Arrays in left und right anlegt. Die Funktion allokiert dazu jeweils mit make() den Speicher für einen Array der gewünschten Länge und ruft anschließend ab Zeile 28 die in Go eingebaute Funktion copy() auf und übergibt ihr die Anfangsposition des zu kopierenden Arrays mit a[p:] a[q+1:] ("Element an Index p bzw. q+1 und folgende"). Da copy() nur soviele Zeichen kopiert wie in den Array passen, stimmt auch die Anzahl der tatsächlich kopierten Zeichen.
Anschließend läuft die for-Schleife ab Zeile 38 durch die zwei Arrays, entfernt jeweils das kleinere aktuelle Element und bricht ab, falls eines der Arrays aufgebraucht ist. Die restlichen Elemente des anderen Arrays kopiert dann eine der beiden for-Schleifen ab Zeile 49 beziehungsweise 54 ins Ergebnis-Array.
 |
| Abbildung 7: Die Funktion merge() im Mergesort kombiniert zwei sortierte Stapel (oben) zu einem (unten), in dem sie für den nächsten Schritt immer den oberen Stapel mit der niedrigeren Karte wählt. |
 |
| Abbildung 8: Der hochrekursive Merge-Sort ist schnell, braucht aber extra Speicher. |
Der Hauptfunktion mergesort() ab Zeile 15 in Listing 4, die den Array, sowie die Indexpositionen von Anfang und Ende entgegennimmt, bleibt nur noch, den ihr übergebenen Array in zwei Teile zu teilen, sich selbst rekursiv auf die beiden Teil-Arrays aufzurufen, und die beiden Ergebnisse mit merge() zusammenzufügen. Die Rekursion wiederholt sich so lange, bis mergesort() ein Array mit nur einem Element erhält (also ist p == r und damit die if-Bedingung falsch) und mergesort() einfach zurückkehrt. Abbildung 7 zeigt, wie der Algorithmus schrittweise einen Array mit sieben Integern sortiert.
Doch im Normalfall muss niemand Sortieralgorithmen in Go von Hand kodieren. Go bietet eingebaute Sortierfunktionen für String- und Integer- oder Float-Slices. Nach dem Importieren des sort-Pakets stehen sort.Ints(), sort.Float64s sowie sort.Strings() bereit, die jeweils ein Slice von Integer-, Float- oder Strings in eine aufsteigende Reihenfolge bringen, in dem sie die Arrays jeweils in-place sortieren.
01 package main
02
03 import (
04 "fmt"
05 "sort"
06 )
07
08 func main() {
09 things := []string{"green", "red", "blue", "black", "white"}
10
11 sort.Strings(things)
12
13 fmt.Printf("%+v\n", things)
14 }
Wie man im Go-Source-Code auf [6] nachlesen kann, nutzt Go dafür den Quicksort-Algorithmus (Abbildungen 8 und 9). Quicksort ist ebenfalls ein Divide-and-Conquer-Mechanismus und ist fast durchgehend rasend schnell. Meist kommt er in nur O(n*log(n)) Schritten ans Ziel. Allerdings flippt er in seltenen Fällen total aus und braucht sagenhafte O(n^2) Schritte, was bei einer Million Einträgen ein Unterschied zwischen Sekunden und Jahren ist. Wenn der Algorithmus mit hundertprozentiger Sicherheit terminieren muss, sind andere Verfahren manchmal besser. Um diese Ausreißer abzuwehren, bauen Standard-Libraries von Programmiersprachen aber oft Verfahren ein, den Algorithmus leicht abändern und die Katastrophe abwenden.
 |
|
Abbildung 9: Auch die Standardfunktion C |
 |
| Abbildung 10: Die Standardbibliothek implementiert den Quicksort-Algorithmus für die Sortierung. |
Verwöhnte Skriptjünger reiben sich verwundert die Augen, denn Gos strenges Typsystem fordert einiges an Mehraufwand, um einen Array von beliebigen Daten zu sortieren. So ist es unmöglich, eine Sortroutine zu definieren, die Arrays mit Elementedn eines generischen Datentyps sortiert, vielmehr muss der Programmierer explizit festlegen, wie Go die Elemente vergleicht und vertauscht.
01 package main
02
03 import (
04 "fmt"
05 "sort"
06 )
07
08 type Record struct {
09 id int
10 }
11
12 type Records []Record
13
14 func (r Records) Len() int {
15 return len(r)
16 }
17
18 func (r Records) Swap(i, j int) {
19 r[i], r[j] = r[j], r[i]
20 }
21
22 func (r Records) Less(i, j int) bool {
23 return r[i].id < r[j].id
24 }
25
26 func main() {
27 data := Records{{5}, {1}, {2}, {7}, {3}}
28 sort.Sort(data)
29 fmt.Printf("%+v\n", data)
30 }
So definiert Listing 6 eine fiktive Datenstruktur Record, die lediglich einen Integerwert als Attribut enthält. Um nun einen Array mit Elementen aus Record-Typen zu sortieren, muss der Programmierer Go beibringen, wie es die Länge des Arrays mit den Datentypen ermittelt, wie es zwei Elemente an den Positionen i und j miteinander vergleicht und wie es zwei verschiedene Einträge miteinander vertauscht -- eben alles was eine Sortierfunktion intern so mit den Daten macht.
Hierzu definiert Listing 6 die Funktionen Len(), Swap() und Less() und weist ihnen jeweils einen Receiver vom Typ Records (also einem Array von Record-Typen) zu. Die Länge des Arrays bestimmt sie einfach mit der eingebauten Go-Funktion len(), vertauscht werden zwei Elemente mit Gos praktischer Vertauschsyntax (a,b = b,a) und der Vergleich zweier Elemente erfolgt mit dem "Kleiner als"-Operator lt, wie Zeile 23 zeigt.
Damit Go den Array in-place mit Quicksort sortiert, ruft Zeile 28 die Funktion sort.Sort() auf und übergibt ihr den Array mit den Record-Elementen. Prompt kommt das Ergebnis korrekt als
$ ./sortstruct
[{id:1} {id:2} {id:3} {id:5} {id:7}]zurück. Es zeigt sich, dass eine Sprache wie Go mit strenger Typprüfung sicher etwas mehr Programmieraufwand erfordert als eine Skriptsprache, die klaglos Strings und Integer und Floats ohne Meckern gleichermaßen sortierte, oder der man einfach eine hausgemachte Sortierfunktion für selbstdefinierte Typen mitgeben könnte. Wieder wett macht Go den Nachteil durch seine hohe Verarbeitungsgeschwindigkeit und die Tatsache, dass der Compiler schon Fehler bei versehentlichen Typfehlern meldet, und nicht erst das Programm zur Laufzeit.
Listings zu diesem Artikel: http://www.linux-magazin.de/static/listings/magazin/2020/01/snapshot/
Michael Schilli, "Titel": Linux-Magazin 12/16, S.104, <U>http://www.linux-magazin.de/Ausgaben/2016/12/Perl-Snapshot<U>
"Countingsort", https://de.wikipedia.org/wiki/Countingsort
Knuth, "The Art of Computer Programming Volume 3: Searching and Sorting", 1998
Cormen, Leiserson, Rivest, Stein, "Introduction to Algorithms", 2003
Implementierung der Sort-Funktionen in der Go Standard Library, https://golang.org/src/sort/sort.go
 |
Michael Schilliarbeitet als Software-Engineer in der San Francisco Bay Area in Kalifornien. In seiner seit 1997 laufenden Kolumne forscht er jeden Monat nach praktischen Anwendungen verschiedener Programmiersprachen. Unter mschilli@perlmeister.com beantwortet er gerne Ihre Fragen. |
Hey! The above document had some coding errors, which are explained below:
Unknown directive: =desc