
Bei näherer Inspektion eines Produkts auf Amazon, das durchgehend mit 5-Sterne-Wertungen glänzt, stellt sich oft heraus, dass viele Bewertungen offensichtlich von professionellen Schergen stammen. Die Texte verraten oft, dass der Schreiberling sich offensichtlich gar nicht mit dem Artikel befasst hat ("Tolles Produkt, schnelle Lieferung!"), und forscht man dann nach weiteren Bewertungen desselben Kunden, finden sich oft weiter 5-Sterne-Reviews mit ähnlichen Satzhülsen. Mittlerweile ist das Problem auf Amazon so offensichtlich, dass sich Kunden verwundert die Augen reiben, warum der Online-Riese nicht endlich einschreitet.
Bei der Ermittlung solcher und ähnlicher Schwindeleien können Graphdatenbanken helfen. Meist sind es mehrere Kriterien, die Muster im typischen Verhalten von Betrügern erkennen und diese auffliegen lassen. Schreibt ein einziger Kunde hunderte von 5-Sterne-Bewertungen? Verdächtig. Stehen bei einem Produkt viele dieser 08/15-Bewertungstexte? Daran könnte etwas faul sein. Oder bewerten die Mitglieder eines Gaunerrings alle die gleichen Produkte? Schlägt nun ein Alarmsystem bei nur einer dieser Kriterien an, liegt vielleicht nicht unbedingt Missbrauch vor, bei zweien oder mehreren hingegen erhöht sich die Wahrscheinlichkeit und weiteres Nachbohren würde sich lohnen -- wenn ein Interesse daran besteht, Kunden nicht übers Ohr zu hauen.
Das letzte vorher genannte Kriterium ist programmiertechnisch interessant: Wie findet ein Algorithmus Gruppen von Usern, die alle die gleichen Produkte bewerten, ohne dass er Hinweise dafür hat, welche User das nun sind? Listing 1 zeigt eine fiktive Yaml-Liste von Produkten mit den Namen der Bewerter. Eine ähnliche Liste ließe sich mit echten Daten von der Amazon-Webseite mittels der offiziellen API oder einem Scraper einholen.
01 reviews:
02 product1:
03 - reviewer1
04 - reviewer2
05 - reviewer3
06 - reviewer7
07 product2:
08 - reviewer1
09 - reviewer2
10 - reviewer4
11 - reviewer8
12 product3:
13 - reviewer3
14 product4:
15 - reviewer4
16 - reviewer7
17 product5:
18 - reviewer5
19 - reviewer8
20 product6:
21 - reviewer6
Das menschliche Auge erkennt sofort, dass das Gaunerduo reviewer1/2 offensichtlich zusammen die Produkte product1/2 bewertet hat. Lägen die Daten nun in einem relationalen Datenmodell vor, wäre es sehr aufwändig, diesen Zusammenhang bei einer einigermaßen voluminösen Kundendatenbank in endlicher Zeit herauszufinden. Mit Graphdatenbanken, die statt mit relationalen Tabellen und teuren Join-Kommandos zu jonglieren einfach Relationen zwischen Knoten abwandern, lassen sich aber relativ einfach schlaue Algorithmen programmieren. Der Programmier Snapshot, seiner Zeit wie immer voraus, hat sich schon vor sechs Jahren mit dem Thema befasst ([2]), aber die Entwicklung des Genres ist nicht stehengeblieben und legitimiert eine neue Runde.
Das in dieser Ausgabe vorgestellte Go-Programm wandelt die Yaml-Liste aus Listing 1 in einen Graphen um, der anzeigt, welche Produkte von welchen Personen bewertet wurden. Hierzu setzt es Kommandos an eine lokal installierte Neo4j-Datenbank ab, die nach Ablauf des Programms den in Abbildung 1 gezeigten Graphen mit den Relationen zwischen Produkten und Bewertern anzeigt. Der Screenshot stammt aus dem Fenster eines Webbrowsers, der mit http://localhost:7474 auf eine Neo4j-Installation zeigt, die in einem Container praktischerweise nicht nur den Server, sondern auch ein Web-Interface zur graphischen Aufhübschung der Daten bereitstellt.
| |
| Abbildung 1: Unter http://localhost:7474 erscheint der Beziehungsgraph in Neo4j im Browser. |
Wurden die Daten erstmal in den Neo4j-Server eingetütet, kann der User mittels interaktiver Kommandos in der sogenannten Cypher-Shell Abfragen absetzen und Analysen starten. Abbildung 2 zeigt den Aufruf des Similarity-Algorithmus ([4]) aus einem Neo4j-Plugin mit wissenschaftlichen Tools.
Der Algorithmus findet Knoten im Graphen, die über ihre Relationen mit möglichst vielen gemeinsamen Nachbarn verbunden sind, und nennt diese dann "ähnlich". Den numerischen Grad der Ähnlichkeit errechnet er aus dem Jaccard-Koeffizienten ([5]) der Kandidaten. Abbildung 2 zeigt das Ergebnis: offensichtlich hat der Algorithmus festgestellt, dass die beiden Bewerter Reviewer 1 und 2 gemeinsam die Produkte 1 und 2 bewertet haben und den beiden Schlingeln deswegen den numerischen Ähnlichkeitswert 1 zugewiesen. Beweis für unlautere Machenschaften ist das freilich noch keiner, aber das Ergebnis zeigt zumindest an, wo man im Verdachtsfall nachbohren könnte, um weitere Indizien aufzudecken.
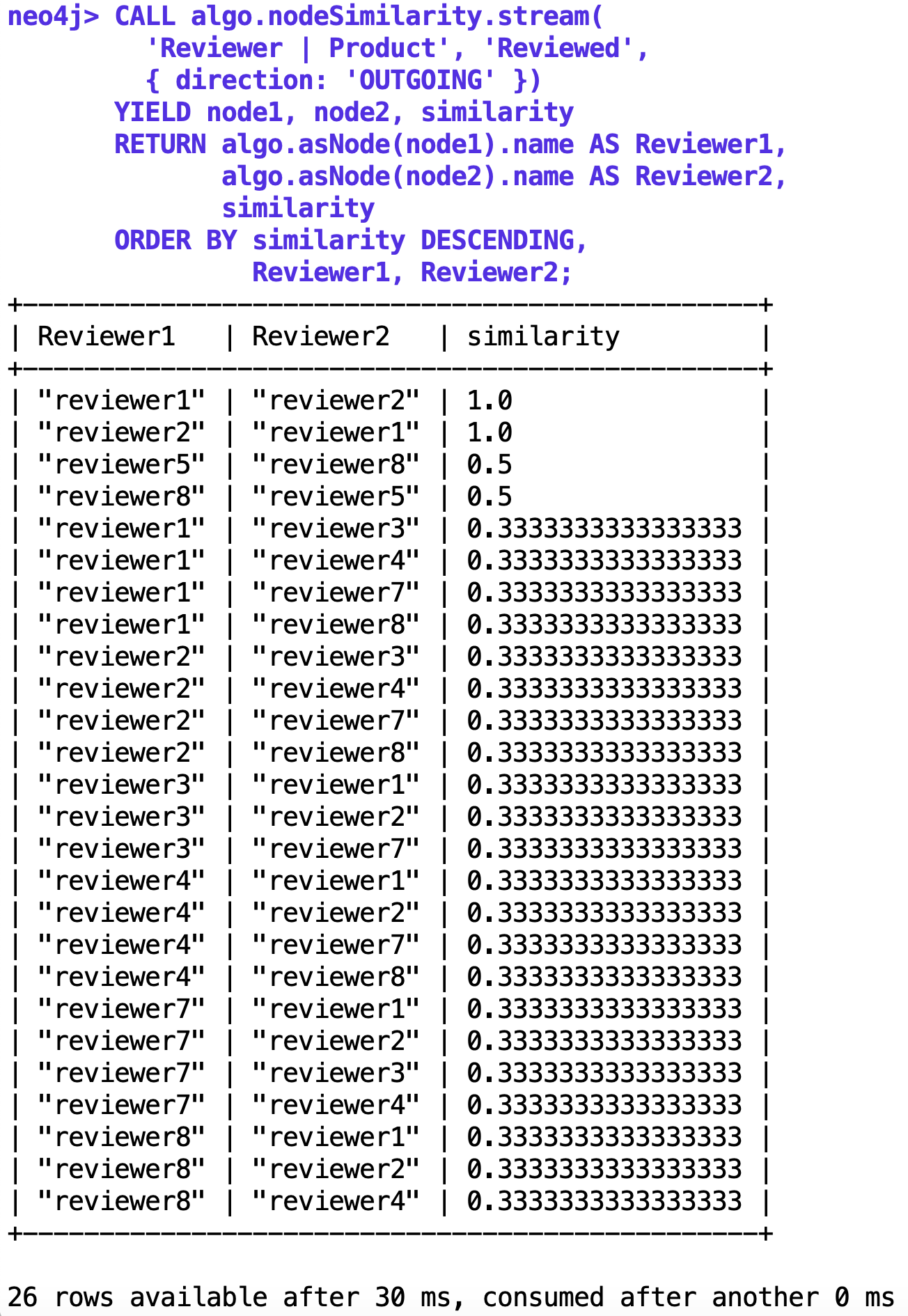 |
| Abbildung 2: Der Similarity-Algorithmus has reviewer1/2 als verdächtig markiert. |
Interessant am Ergebnis ist auch, dass andere Bewerter ebenfalls mehrere Produkte bewertet haben, allerdings nicht mit einem Kompagnon die gleichen, und deswegen einen niedrigeren Ähnlichkeitswert bekamen. Reviewer 8 hat zum Beispiel die Produkte 2 und 5 bewertet, Reviewer 4 die Produkte 2 und 4, und beide erhielten nur 0.5 auf der Ähnlichkeitsskala, weil ihr Verhalten unverdächtiger war.
Um eine Neo4j-Instanz auf dem heimischen Rechner zu installieren, eignet sich am besten ein Docker-Container, den das Kommando docker run in Abbildung 3 vom Netz holt und darin einen Neo4j-Server startet. Anschließend springt der User mittels docker exec in den Container und kann dort die interactive Neo4j-Cypher-Shell öffnen, um Kommandos an den Server abzusetzen.
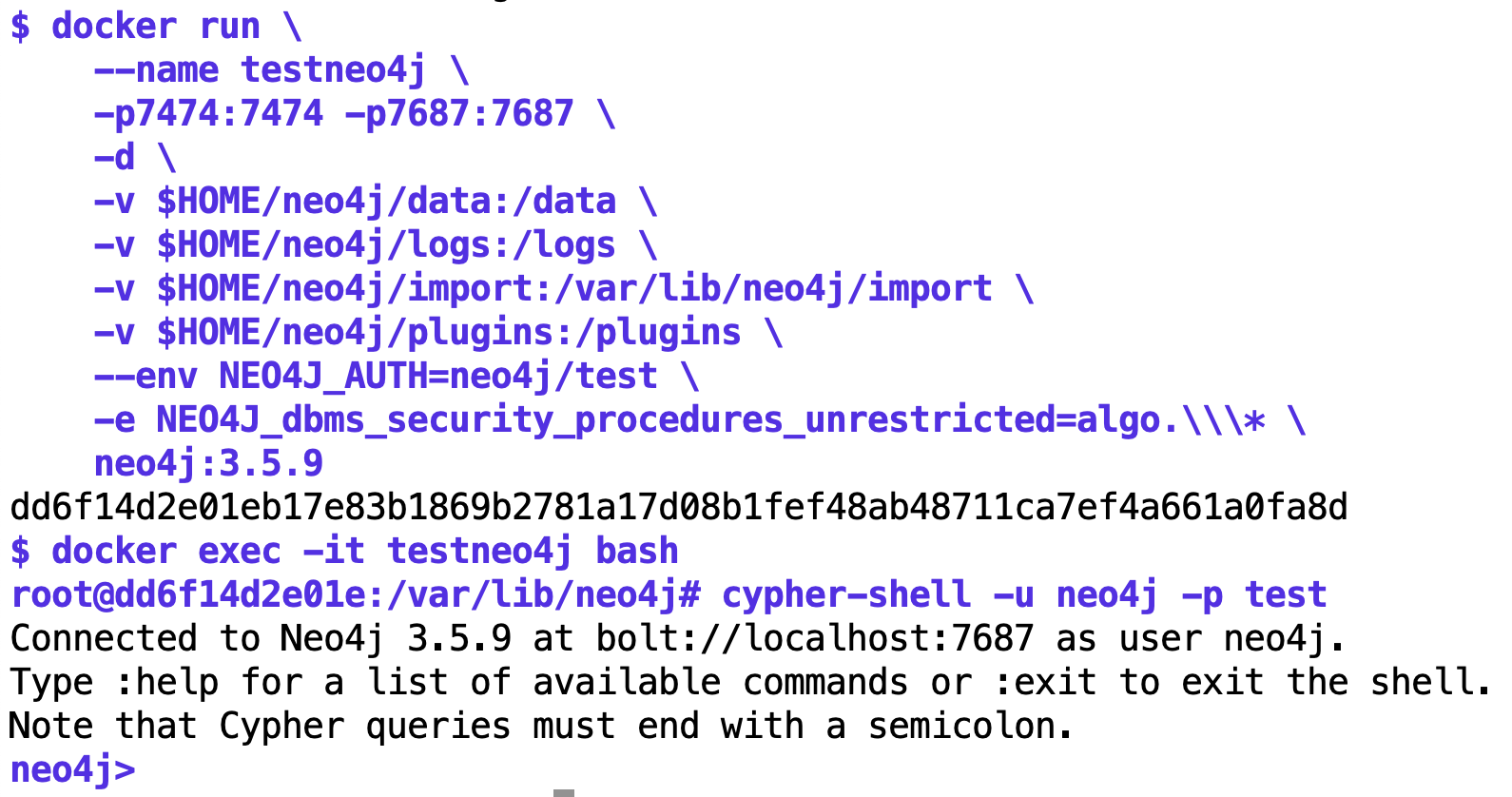 |
| Abbildung 3: Docker-Kommandos holen Neo4j vom Netz, starten den Server in einem Container und öffnen die interaktive Cypher-Shell. |
Damit Browser und API-Skripts von außen auf den containerisierten Neo4j-Server zugreifen können, exportiert der Aufruf in Abbildung 3 die Ports 7474 und 7687 vom Container auf den Host-Rechner. Dort kann dann der User über http://localhost:7474 mit dem Browser auf den Neo4j-Webserver zugreifen. Nach dem Einfüttern der Daten in Neo4j zeigt die Browser-Ansicht in Abbildung 1 auf http://localhost:7474 das soweit gediegene Relationsmodell. Auf Port 7687 lauscht der Server im Container auf Kommandos der von Neo4j offiziell genutzter Bolt-API, mit der Skripts die Datenbank abfragen und neue Daten einspeisen können.
Weiter verbindet der Docker-Aufruf die Verzeichnisse data, logs, import und plugins des Hosts mit der Innenseite des Containers, damit Host und Container Datenbankdaten und Logs austauschen können, und der User unter plugins neue Plugins vom Netz laden und dem Container unterjubeln kann.
Läuft der Server erstmal im Container kann nun das Go-Programm aus der Yaml-Liste der Review-Daten Neo4j-Kommandos formen, um die Relationsdaten in die Datenbank einzuspeisen. Hierzu legt es zunächst die Knoten vom Typ Reviewer und Product an, um darauf zwischen beiden eine Relation reviewed einzuhängen. Listing 2 zeigt die dafür notwendigen Neo4j-Kommandos, die der User auch von Hand in die Cypher-Shell eingeben könnte.
01 MERGE (product1:Product {name:'product1'})
02 MERGE (reviewer1:Reviewer {name:'reviewer1'})
03 MERGE (reviewer1)-[:Reviewed {name: 'reviewed'}]-(product1)
04 MERGE (reviewer2:Reviewer {name:'reviewer2'})
05 MERGE (reviewer2)-[:Reviewed {name: 'reviewed'}]-(product1)
06 MERGE (reviewer3:Reviewer {name:'reviewer3'})
07 MERGE (reviewer3)-[:Reviewed {name: 'reviewed'}]-(product1)
08 MERGE (reviewer7:Reviewer {name:'reviewer7'})
09 MERGE (reviewer7)-[:Reviewed {name: 'reviewed'}]-(product1)
10 ...
Dabei erzeugt das MERGE-Kommando in Listing 2 jeweils einen neuen Eintrag, entweder einen Knoten oder eine Relation. Dies könnte genausogut ein CREATE-Kommando bewerkstelligen, MERGE flippt nur nicht gleich aus, falls der Eintrag schon existiert. Zeile 1 legt einen neuen Knoten vom Typ Product an, weist ihm das name-Attribut produckt1 zu und hält eine Referenz darauf in der Variablen product1 fest. Ähnliches geschieht mit einem Reviewer-Knoten in Zeile 2, und Zeile 3 verknüpft dann die vorher definierten Variablen reviewer1 und product1 mit einer Beziehung vom Typ Reviewed, die das name-Attribut auf reviewed setzt.
Alle Daten händisch einzugeben würde den User schnell ermüden, deshalb automatisiert das Go-Programm in Listing 3 die Generierung einer Liste von Neo4j-Kommandos aus der Yaml-Liste und setzt sie über Port 7474 an den im Container laufenden Neo4j-Server ab.
01 package main
02
03 import (
04 "database/sql"
05 "fmt"
06 _ "gopkg.in/cq.v1"
07 "gopkg.in/yaml.v2"
08 "io/ioutil"
09 "log"
10 )
11
12 type Config struct {
13 Reviews map[string][]string
14 }
15
16 func main() {
17 yamlFile := "reviews.yaml"
18 data, err := ioutil.ReadFile(yamlFile)
19 if err != nil {
20 log.Fatal(err)
21 }
22
23 var config Config
24 err = yaml.Unmarshal(data, &config)
25 if err != nil {
26 log.Fatal(err)
27 }
28
29 created := map[string]bool{}
30 cmd := ""
31 // nuke all content
32 toNeo4j(`MATCH (n) OPTIONAL MATCH
33 (n)-[r]-() DELETE n,r;`)
34
35 for prod, reviewers :=
36 range config.Reviews {
37 for _, rev := range reviewers {
38 if _, ok := created[prod]; !ok {
39 cmd += fmt.Sprintf(
40 "MERGE (%s:Product {name:'%s'})\n",
41 prod, prod)
42 created[prod] = true
43 }
44 if _, ok := created[rev]; !ok {
45 cmd += fmt.Sprintf(
46 "MERGE (%s:Reviewer {name:'%s'})\n",
47 rev, rev)
48 created[rev] = true
49 }
50 cmd += fmt.Sprintf(
51 "MERGE (%s)-[:Reviewed " +
52 "{name: 'reviewed'}]-(%s)\n",
53 rev, prod)
54 }
55 }
56 cmd += ";"
57 toNeo4j(cmd)
58 }
59
60 func toNeo4j(cmd string) {
61 db, err := sql.Open("neo4j-cypher",
62 "http://neo4j:test@localhost:7474")
63 if err != nil {
64 log.Fatal(err)
65 }
66 defer db.Close()
67
68 _, err = db.Exec(cmd)
69
70 if err != nil {
71 log.Fatal(err)
72 }
73 }
Listing 3 nutzt das offizielle Yaml-Modul der Go-Welt, um die nach dem Einlesen mittels io/ioutil als Byte-Array vorliegenden Yaml-Daten per Unmarshal() in eine Go-Datenstruktur zu transponieren. Das typstrenge Go integriert das eher legere Yaml hier recht salopp, indem es eine über Strings indizierte Hashtabelle mit Einträgen definiert, die aus Arrays von Strings bestehen. Die Struktur vom Typ Config ab Zeile 12 definiert die Hash-Map mit den verschachtelten String-Arrays unter dem Eintrag Reviews. Großschreibung ist hier wichtig, damit das Yaml-Modul darauf zugreifen kann.
Ab Zeile 35 iterieren dann zwei for-Schleifen über alle Produkte in der Hash-Map, und dann für jeden Eintrag über den Array von Reviewern. Bevor nun Zeile 50 das Kommando für die Relation zusammenstellt, prüfen die if-Bedingungen der Zeilen 38 und 44, ob die beiden Endpunkte der Relation schon als Knoten in der Datenbank existieren. Zeigt die Map-Variable created an, dass ein Knoten noch fehlt, fügt der Code ein MERGE-Kommando zur dessen Erzeugung an den cmd-String an, der alle Kommandos durch Zeilenumbrüche getrennt aufkumuliert. In diesem Fall ist es wichtig, Neo4j keine Semicolon-separierten Kommandos zu schicken, falls in einigen Variablen definiert wurden (zum Beispiel reviewer1), die dann später (beim Erzeugen der Relation) wiederverwendet werden. Ein Semicolon schließt ein Kommando ab, und Neo4j vergisst alle vorher definierten Variablen.
Um den in cmd zusammengebauten Kommandostring zum Einfügen der Daten sowie ein vorausgehendes Kommando zur Löschung aller bisherigen Daten an den Server zu schicken, kontaktiert die Funktinon toNeo4j() ab Zeile 60 den Browser-Port des Servers im Container. Das verwendete Open-Source-Paket cq auf Github ist schon etwas in die Jahre gekommen und nutzt nicht den Bolt-Anschluss des offiziell von Neo4j unterstützten API-Moduls auf Port 7687, funktioniert aber einwandfrei und ist einfacher zu installieren als das Original, das zum Herunterladen irgendwelcher obskurer Bolt-Binaries zwingt.
In SQL-Manier nimmt Zeile 61 Kontakt zum eingedosten Server im Container auf. Zeile 68 schickt mit Exec() das in cmd vorliegende Kommando über den Port, was der Server mit einer Fehlermeldung quittiert, falls etwas schiefgegangen ist. Mit der Befehlsfolge
go mod init rimport
go buildholt go die zum Erstellen des Binaries erforderlichen Libraries von Github ab und erzeugt das ausführbare Programm rimport. Aufgerufen liest letzteres erst die Datei reviews.yaml von der Platte und pumpt dann die notwendigen Kommandos über den Container-Port an den Neo4j-Server. Anschließend kann der User Abfragen zur Betrugsaufdeckung auf das Datenmodell abschicken, wie vorher in Abbildung 2 gezeigt.
Das aktuelle Docker-Image neo4j:latest schleppt die neueste Neo4j-Version 4.0.3 an, die allerdings noch keinerlei Graph-Algorithmen kann. Um diese nachzuinstallieren, muss der User eine .jar-Datei von der Neo4j-Seite herunterladen ([3]) und im Verzeichnis ~/neo4j/plugins ablegen. Dort schnappt sich der Docker-Container beim Start des Neo4j-Servers, denn das docker run Kommando in Abbildung 3 importiert das Plugin-Verzeichnis über die Option -v.
Doch halt, nicht so schnell! Der Graph-Algorithms-Plugin liegt nur in Version 3.5.9 vor, und wer meint, er könne diesen einfach einer Neo4j-Datenbank in Version 4.0.3 unterjubeln, irrt gewaltig, und sieht den Container gleich nach dem Neustart flugs die Botten mit einem langen aber völlig nichtssagenden Stacktrace hinwerfen. Wer allerdings in weiser Voraussicht statt neo4j:latest einfach neo4j:3.5.9 installiert, hat mehr Glück. Der Server startet ordnungsgemäß und die Datenbankabfrage nach Algorithmen im algo.*-Namespace fördert eine lange Liste zutage (Abbildung 4).
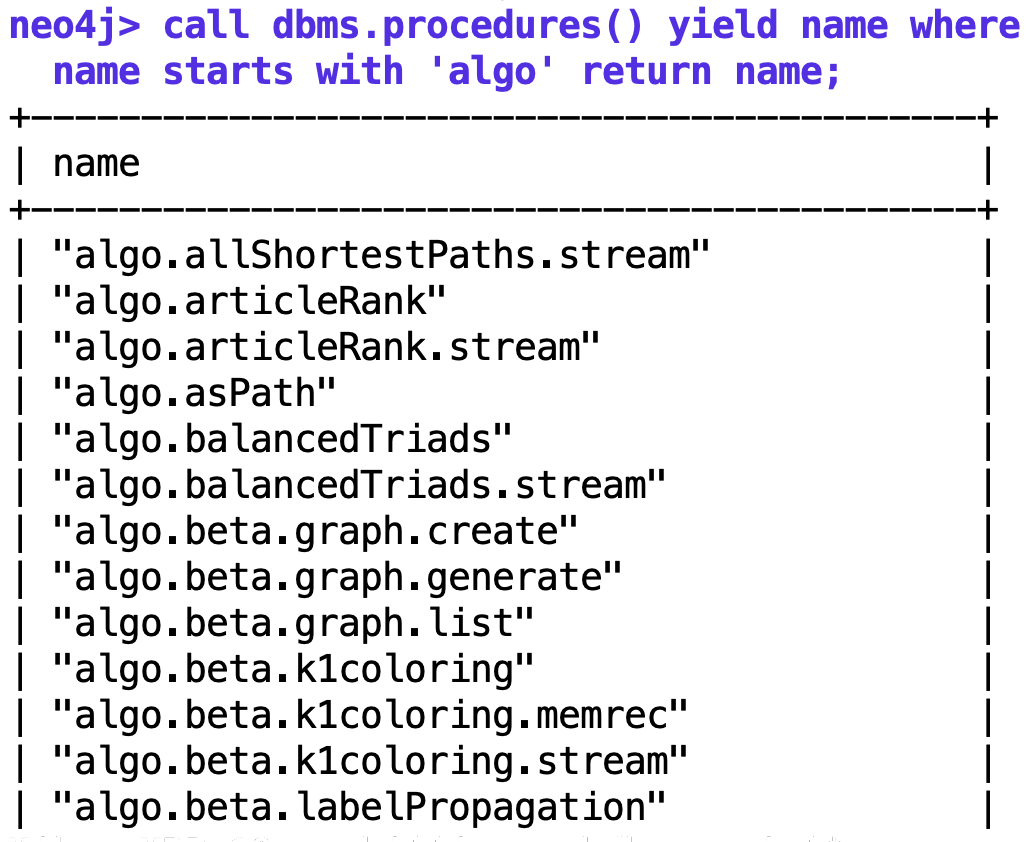 |
| Abbildung 4: Nach der Installation des Graph-Algorithms-Plugins zeigt Neo4j die nachgeladenen Algorithmen an. |
Doch, oh weh, noch mehr Steine liegen im Weg! Wer nun versucht, einen der Algorithmen tatsächlich zu verwenden, bekommt eine Fehlermeldung auf den Schirm, die erklärt, dass dies aus sicherheitstechnischen Gründen in einem "Sandkasten" nicht möglich sei. Vielmehr sei es erforderlich, die importierten Algorithmen von den routinemäßig auferlegten Beschränkungen auszunehmen, indem die Environment-Variable NEO4J_dbms_security_procedures_unrestricted mittels eines regulären Ausdrucks festlegt, dass alles unter dem Namensraum algo freie Bahn genießt. Das Docker-Kommando in Abbildung 3 setzt die Variable bereits ordnungsgemäß. Auch setzt es die Variable NEO4J_AUTH auf neo4j/test, was den Server anweist, den sonst zwingend angeforderten Passwort-Reset zu unterlassen. Der Spaß kann beginnen.
Listings zu diesem Artikel: http://www.linux-magazin.de/static/listings/magazin/2020/05/snapshot/
Michael Schilli, "So'n Beziehungsding": Linux-Magazin 06/14, S.xxx, <U>https://www.linux-magazin.de/ausgaben/2014/06/perl-snapshot/<U>
Algo-Plugin für Neo4j nachinstallieren: https://neo4j.com/docs/graph-algorithms/current/introduction/#_installation
Similarity-Algorithmus in Neo4j: https://neo4j.com/docs/graph-algorithms/current/algorithms/node-similarity/
Jaccard-Koeffizient: https://de.wikipedia.org/wiki/Jaccard-Koeffizient
 |
Michael Schilliarbeitet als Software-Engineer in der San Francisco Bay Area in Kalifornien. In seiner seit 1997 laufenden Kolumne forscht er jeden Monat nach praktischen Anwendungen verschiedener Programmiersprachen. Unter mschilli@perlmeister.com beantwortet er gerne Ihre Fragen. |
Hey! The above document had some coding errors, which are explained below:
Unknown directive: =desc